
Banco de Dados - SQL Server
SQL Server 2005 - Log Shipping – Entendendo, habilitando e configurando
Este artigo tem o objetivo de explicar, habilitar e configurar o log shipping em um cenário real com um ambiente de exemplo.
por Diego NogareEste artigo tem o objetivo de explicar, habilitar e configurar o log shipping em um cenário real com um ambiente de exemplo. A visualização de relatórios do monitor, e o log shipping funcionando, ficará para outro artigo. Em breve, este novo artigo será publicado.
Entendendo o Log Shipping
O log shipping é um recurso que pode (e deve) ser configurado no SQL Server 2005 para realizar cópia periódica de banco de dados entre servidores. Este recurso é aplicado em diversos cenários imagináveis. O mais comum é quando existe um servidor de produção, um de teste e um de desenvolvimento. O servidor de produção nunca deve ser utilizado para desenvolver e testar alterações em seus bancos de dados. Estas alterações são realizadas no servidor de desenvolvimento e testadas no servidor de testes. Como as modificações e testes devem sempre estar o mais próximo possível do real, então os servidores de desenvolvimento e de testes devem ter suas estruturas e seus dados atualizados de acordo com o servidor de produção. Abaixo temos uma representação do cenário que exemplificamos.
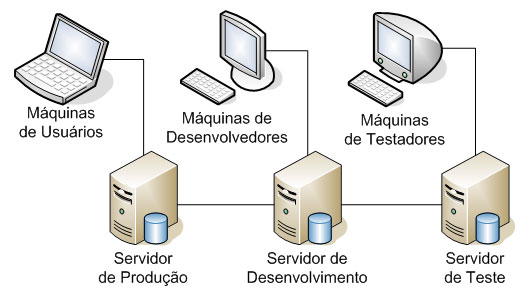
O processo do log shipping é relativamente simples, são alguns passos realizados nos servidores envolvidos no processo que fazem todo o trabalho. Primeiro, é feito um backup dos dados do servidor principal, no nosso exemplo, o de produção. Este backup é gravado fisicamente em uma pasta compartilhada que é acessada por este e outros servidores. Os outros servidores são chamados de secundários, e no exemplo estão representados pelo servidor de desenvolvimento e de teste. Depois de ser feito o Backup do banco, ele é copiado para uma pasta específica em cada servidor secundário. Depois de copiado, o backup é restaurado. Um servidor de monitoramento pode ser configurado e ele registrará todos os passos do servidor principal e dos secundários. Se não configurar o monitoramento, cada servidor registra suas próprias ações. Este monitor registra os históricos, status dos backups e restaurações, e pode disparar alerta se alguma operação agendada falhar. O responsável pela configuração do log shipping pode especificar quando serão feitos os backups, quando serão copiados da pasta compartilhada e quando que serão restaurados nos servidores secundários.
O processo que foi criado no servidor principal é responsável pelo backup do banco, as informações dos históricos e backups antigos são apagados automaticamente de acordo com a configuração que for feita.
Nos servidores secundários, dois processos são habilitados e configurados. O serviço de Cópia e o serviço de Restauração. Ao habilitar estes serviços, processos chamados “Log Shipping Copy” e “Log Shipping Restore” são iniciados dentro do SQL Server Agent. O serviço de Cópia é responsável por acessar a pasta compartilhada, e copiar para uma pasta local do servidor secundário o arquivo de backup que deve ser replicado. O serviço de Restauração é o responsável por restaurar o arquivo que foi copiado. Ambos processos serão executados quando suas clausulas de configuração forem satisfeitas, isso significa que serão executados de acordo com as configurações de tempo que aprenderemos mais a frente.
Um serviço de alerta é criado quando um servidor de monitoramento é utilizado. Este serviço é compartilhado para o servidor principal e os secundários que tenham o log shipping configurado. Qualquer mudança na configuração, ou processo que for executado é registrado pelo serviço de alerta. Este serviço também é iniciado dentro do SQL Server Agent, com o nome de “Log Shipping Alert”.
Abaixo temos uma ilustração do nosso cenário de exemplo, configurado para suportar log shipping.
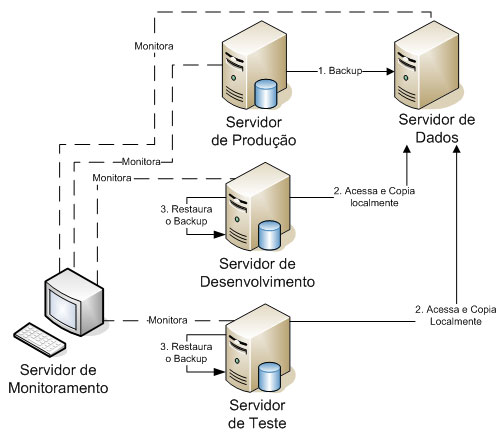
Algumas informações importantes referentes ao Log Shipping
· O Log Shipping é um recurso do SQL Server Standard Edition, Workgroup Edition ou Enterprise Edition. O SQL Server deve estar instalado em todos os servidores que fizerem parte do processo. No SQL Server Express Edition não é possível habilitar e configurar este recurso.
· Os servidores de produção, desenvolvimento e de testes podem ser em um mesmo computador com três instâncias distintas do SQL Server. Isso não é recomendado, mas pode ser feito.
· O servidor de dados é onde o arquivo de backup será compartilhado entre os servidores. O servidor de produção que gravará o arquivo, deverá ter permissão de leitura e escrita na pasta, e os servidores secundários, que copiarão o arquivo de backup, devem possuir permissões de leitura e cópia.
· O servidor de monitoramento deve ser uma máquina separada do servidor principal e dos secundários, para caso algum dos servidores fique “off-line”, o responsável consiga analisar os Logs registrados pelo monitor, e possa tomar as medidas corretas. Isso é uma boa prática, mas não é obrigatório.
· Os bancos de dados que participarão do processo de log shipping devem ser criados com modo de Full Recovery ou Bulk-Logged Recovery. Outros modelos de Recovery não conseguem trabalhar com log shipping e mostram uma mensagem de erro ao tentar utilizar.
· Para utilizar o servidor de monitoramento, ele deve ser configurado na primeira vez que estiver criando o log shipping, depois de salvo o processo sem o servidor de monitoramento, ele não poderá ser configurado. Caso queira configurar o servidor de monitoramento em um log shipping existente, o log shipping antigo deve ser removido, e criado um novo com os mesmos recursos que o anterior. A única diferença será a configuração do servidor de monitoramento.
Habilitando o Log Shipping
A primeira coisa a ser feita para habilitar o log shipping, tanto no banco do servidor principal quanto no banco do servidor secundário, é se conectar aos servidores com usuário que seja SysAdmin do banco que será configurado. Agora que já estamos conectados no banco, e temos permissões suficientes para fazer o trabalho, vamos colocar a mão na massa.
Configurando o Servidor Primário
Vamos até a propriedade do log shipping do banco, para isso, clique com o botão direito do mouse no banco que configuraremos, e vá até Properties.
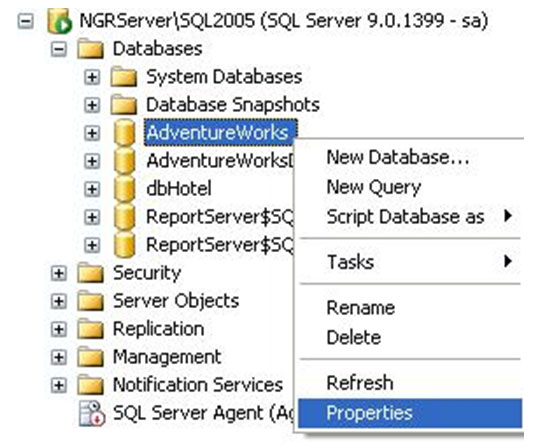
Por padrão, o banco AdventureWorks não está com a opção de Recovery como Full Recovery ou Bulk-Logged Recovery. Vamos alterar a opção para Full Recovery. Para isso, vá até a sessão de Options no menu da esquerda, e altere a opção de Recovery model para Full.
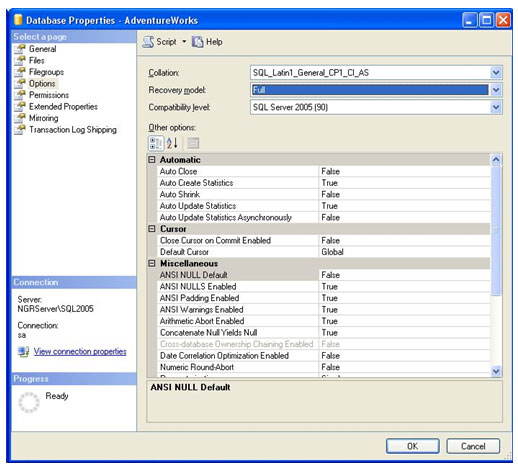
Ainda na janela de propriedades, no menu da esquerda, selecione a sessão Transaction Log Shipping.
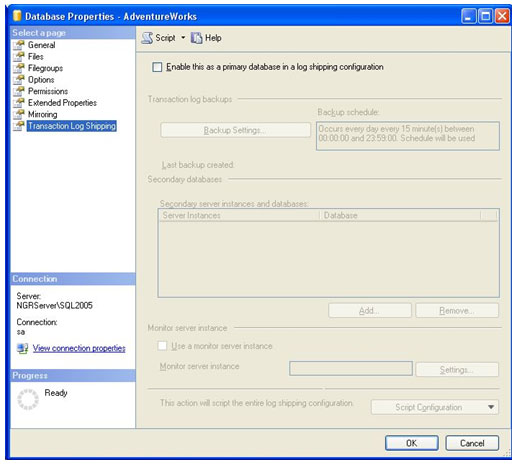
O lado direito da tela será apresentado com as opções que serão utilizadas para a configuração. Por padrão, o log shipping não está habilitado. Para habilitar, clique na opção Enable this as a primary database in a log shipping configuration.
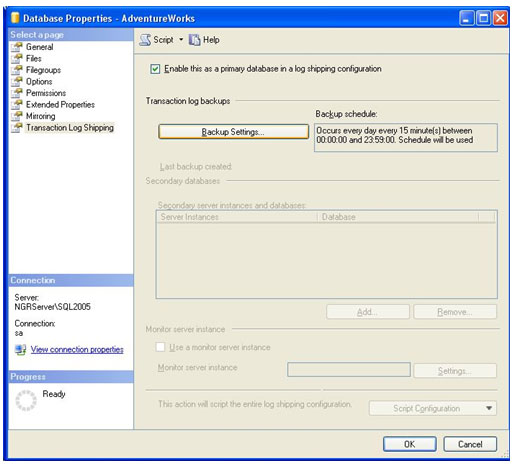
Após a opção ficar checada, a sessão do Transaction Log Backups ficará habilitada. Clique no botão Backup Settings...
Uma nova janela é aberta e, são apresentadas algumas opções para configuração. Na caixa de texto Network path to backup folder, coloque o caminho da pasta compartilhada que foi criada no servidor de dados. Caso o caminho da pasta compartilhada seja no mesmo servidor que o banco está, então coloque o caminho na caixa de texto If the backup folder is located on the primary server, type a local path to the folder. Se a pasta compartilhada estiver em outro servidor, esta ultima caixa de texto pode permanecer em branco. No caso do nosso exemplo, estou usando o mesmo servidor para armazenar os arquivos de backup. Estou usando o mesmo servidor só para exemplificar o artigo, em um cenário sério, isso não deve ser utilizado. Para isso, criei uma pasta chamada LogShipping e mapeei esta pasta na unidade X: da máquina. Escolha a quantidade de horas que os arquivos de backup permanecerão nesta pasta antes de serem apagados automaticamente, e o tempo de espera até um alerta ser disparado caso nenhum backup aconteça no tempo determinado.
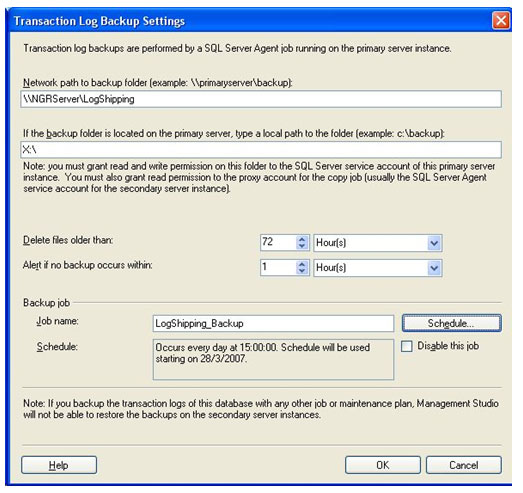
Uma caixa de texto para colocar o Job Name está com um nome padrão, este nome pode ser mudado, no caso do exemplo, vou colocar LogShipping_Backp. Do lado da caixa de texto, tem um botão para configuração de agenda, Schedule..., nele é possível alterar as configurações de execução do serviço.
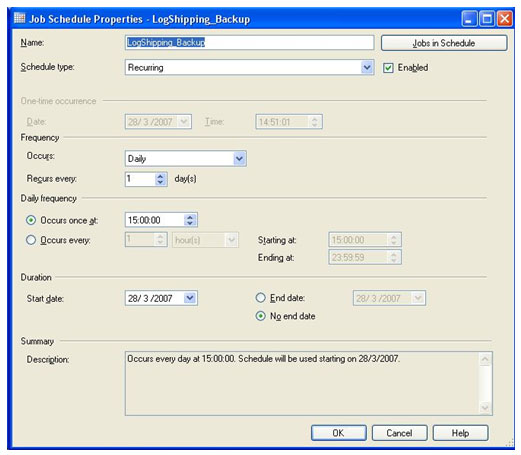
A primeira caixa de texto da nova janela, é onde ficará o nome deste agendamento, uma caixa de opções com o nome de Scheduler Type aparece logo abaixo da caixa que soliciotou o nome. Nesta caixa, mantenha a opção de Recurring selecionada e a opção Enable, que está ao seu lado direito, checada. Estas duas últimas configurações que alteramos, permite customizarmos as opções mais completas de agendamento. As outras opções não permitem uma configuração muito detalhada, mas em diversos casos servem exatamente para a necessidade.
Mantendo a opção Recurring selecionada, as sessões de Frequency, Daily frequence e Duration permitem alterações. Na sessão Frequency, existe mais uma caixa de seleção, mas neste caso, é para selecionar quando que ocorrerão os inícios dos processos. No nosso exemplo, deixaremos a caixa de seleção Occurs com a opção Daily selecionada, e a opção Recurs every com o numero 1 escolhido. Na sessão de Daily frequency configuramos quando que serão disparados os serviços, baseados na sessão anterior, Frequency. Deixaremos a opção Occurs once at selecionada, e a hora que aparece na caixa em frente deixaremos como 15:00:00. A última opção que será alterada, é a sessão de Duration. Nesta sessão configuramos a duração do log shipping, determinando sua data de inicio e caso queira, a data de término. Para ilustrar nosso exemplo, configuramos o Start Date configurado para o dia 28/03/2007 e a opção No end date desmarcada. Clicamos em OK e fechamos esta janela.
Voltando para a tela anterior, já temos um serviço de log shipping configurado no servidor primário. Agora, devemos configurar os servidores secundários e o servidor de monitoramento para finalizarmos o processo completo de log shipping proposto para o artigo.
Configurando o Servidor Secundário
Ainda na mesma tela do Transaction Log Shipping, em Properties, que já estávamos trabalhando, vamos até a sessão de Secondary databases que ficou habilitada, e clicamos em Add...
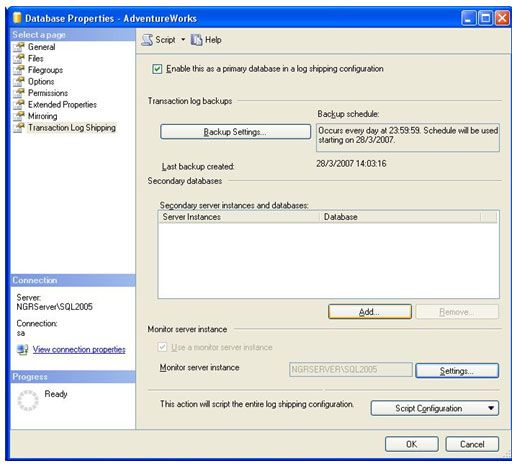
A única coisa que se pode fazer neste instante, é clicar em Connect... para conectar-se à um servidor secundário. A tela de login convencional do SQL Server Manager Studio é apresentada, e solicita para que você se conecte.
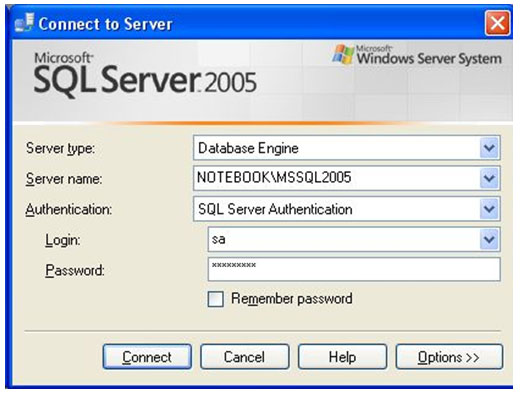
Após a conexão, as opções que estavam desabilitadas, agora permitem alterações. Na caixa de seleção sobre o Secondary database, escolha o banco que estamos trabalhando. No caso do exemplo, AdventureWorks. Existem três abas mais abaixo, na primeira delas, Initialize Secondary Database, você escolhe qual a opção que deve ser utilizada para inicializar o banco.
A primeira opção significa que será gerado um backup completo do primeiro banco e este backup será restaurado em um segundo banco (ele criará o segundo banco, caso ele ainda não exista). No botão Restore Options... que ficará habilitado, escolhemos a pasta que terá o arquivo de dados (.MDF) e o arquivo de log (.LDF). Na segunda opção, ele somente restaura o backup do primeiro banco no segundo, criando o segundo banco, caso ele não exista. Neste caso, o caminho completo onde está o backup deve ser colocado na caixa de texto Backup File. No botão Restore Options... que é habilitado configuramos as mesmas coisas que configuraríamos na opção anterior, o arquivo de dados (.MDF) e o arquivo de log (.LDF). A última opção significa que o segundo banco já está inicializado no servidor secundário. Para nosso exemplo, utilizaremos esta última opção.
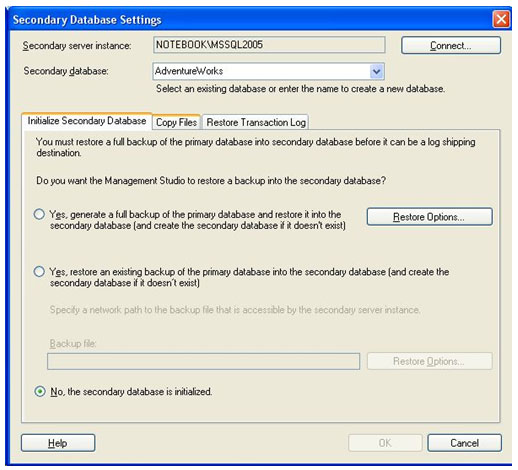
Na segunda aba, Copy Files, indicamos o caminho da pasta local do servidor secundário, onde o serviço de cópia guardará as cópias dos arquivos de backup. No caso do exemplo, uma pasta chamada ArquivosCopiados será utilizada, esta pasta foi criada única e exclusivamente para esta finalidade. Abaixo da caixa de texto que solicita o caminho da pasta local, existe uma opção que configura a quantidade de tempo que os arquivos copiados permanecerão na pasta antes de serem apagados automaticamente. Por padrão são 72 horas, manteremos estes valores. Na sessão Copy Job, existe uma caixa de texto para colocar o nome do serviço de cópia, no exemplo é chamado LogShipping_Copia. Clicando no botão de Schedule... é possível novamente alterar as configurações de agendamento da execução. Configuraremos o serviço de cópia para rodar todos os dias as 15:30:00, a partir do dia 28/03/2007. Se vocês repararem, esta configuração faz com que o serviço de cópia execute sempre 30 minutos depois do serviço de backup ter sido iniciado no servidor principal.
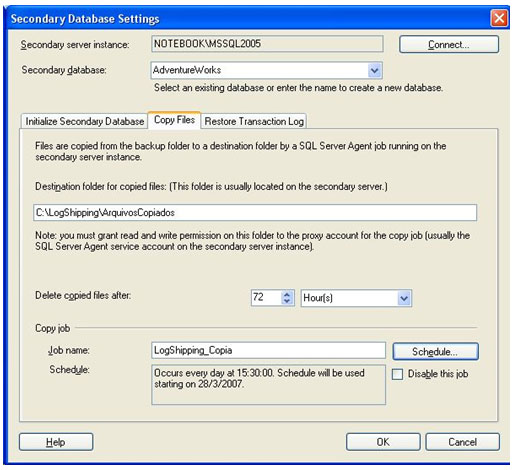
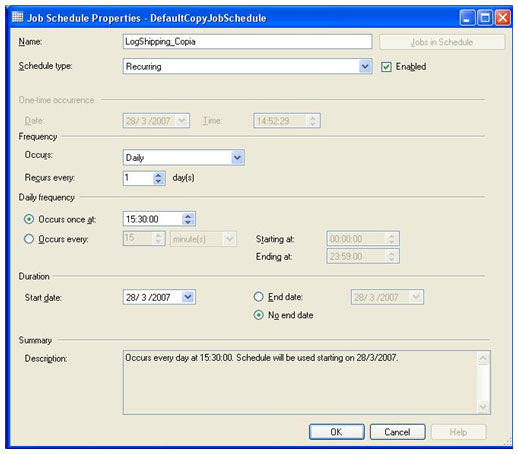
Na terceira e última aba, Restore Transaction Log, é feita a configuração de como será o processo para restaurar o banco, que foi feito copiado para um endereço local na máquina. Na sessão de Database state when restoring backups, existem duas opções para realizar o processo. Recovery Mode e Standby Mode. No exemplo trabalharemos com o Standby Mode, e marcaremos a caixa Disconnect users in the database when restoring backups. Isso desconectará os usuários que estiverem no banco, enquanto o processo de restauração do backup for executado. Manter o padrão do Delay restoring backups at least com o valor zero e Alert if no restore occurs within como sendo de 45 minutos. Neste bloco de configurações que acabamos de alterar, a primeira linha aguardará uma quantidade de minutos, para executar o processo de restaurar o backup, depois de ser iniciado o serviço que restaura o banco. Por este motivo, mantivemos o valor zero. Enquanto a segunda linha dispara um alerta, depois de passar a quantidade de tempo sem ter executado o processo para restauração do banco. Como já estamos acostumados, na sessão Restore Job existe a caixa para colocar o nome do serviço e o botão para configurar sua agenda de execução. No nome do serviço, colocamos LogShipping_Restaura, e o agendmento é para rodar as 16:00:00 de todos os dias, a partir do dia 28/03/2007.
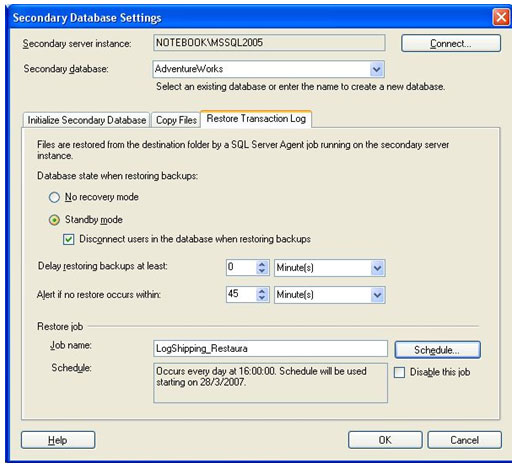
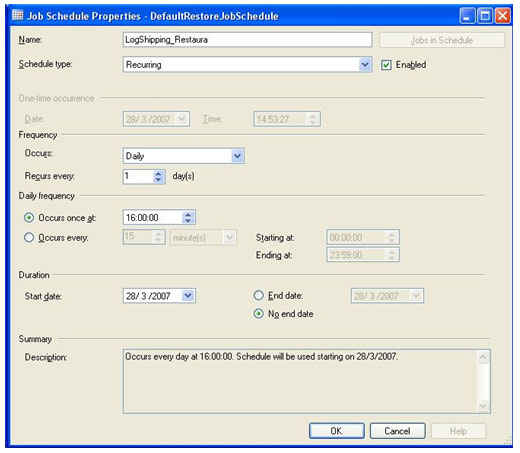
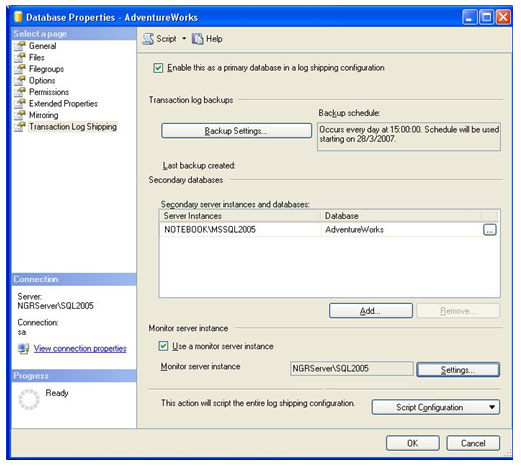
Após o termino das configurações, clique em OK e voltará para a tela de propriedades do banco de dados. Na grid no centro da tela, estão todos os servidores secundários que foram configurados para trabalharem com log shipping neste banco. No nosso exemplo, trabalhamos somente com um servidor secundário, mas é possível trabalhar com mais. Para finalizar o artigo, agora só falta configurar o servidor de monitoramento.
Para configurá-lo, devemos clicar na opção Use a monitor server instance. Ao clicar nesta opção, o botão Settings... é habilitado e é possível alterar suas configurações.
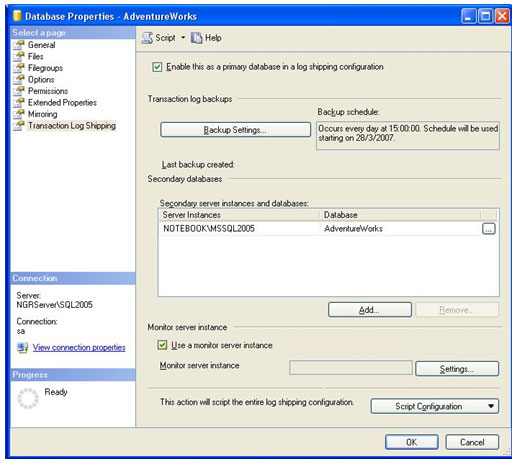
Na tela de configuração do servidor de monitoramento, você deve escolher um servidor para realizar o monitoramento das transações. Clicando em Connect... você se conectará a um servidor do SQL Server que será utilizado como monitor. Depois de conectado, algumas opções já ficam configuradas automaticamente. Na sessão de Monitor connections utilizaremos a opção Using the following SQL Server Login, para manter o usuário e senha que já foi preenchida automaticamente, baseada na conexão que foi realizada. Na sessão de Alert job, como sempre, alteramos o texto do Job Name para algum nome que referencie o serviço. Neste caso, LogShipping_Restaura.
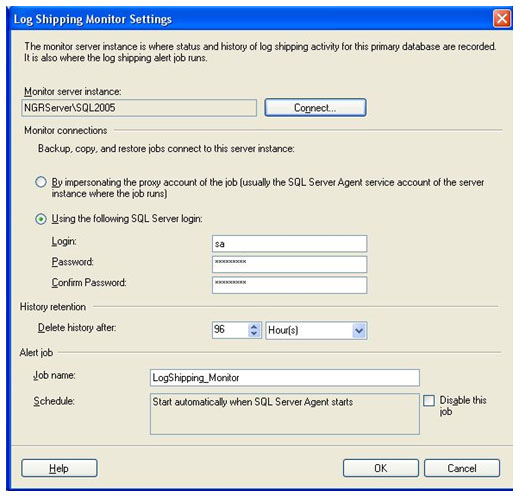
Depois de configuradas as opções, clique em OK para fechar a tela de configurações do monitoramento e voltar para a tela inicial de habilitação do log shipping. Repare, que a tela é sub-dividida em 3 partes. A primeira é para o servidor principal, a segunda para o servidor secundário e a terceira para o servidor de monitoramento.
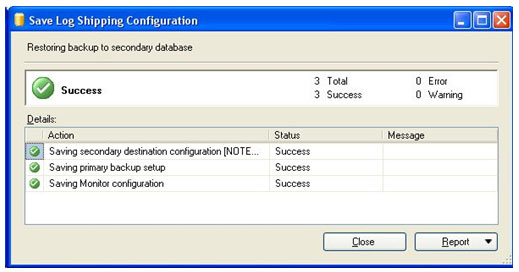
Ao clicar em OK na tela de habilitação do log shipping, uma caixa aparecerá e tentará gravar todas as configurações feitas para o recurso. Ao término da gravação, se todos os status acusarem Success, significa que tudo ocorreu perfeitamente e que seu banco será replicado para os demais servidores assim que o serviço for executado.
Com este recurso, não será mais necessário pedir aos responsáveis pelo servidor restaurar backups, e vocês trabalharão sem medo de alterar alguma coisa acidentalmente em ambiente de produção. Os bancos podem ser configurados para ser replicado do servidor de produção para o de desenvolvimento, e também ser replicado do servidor de desenvolvimento para o de testes. Uma observação que deve ser levada em conta, é que quando um backup é restaurado em um banco, as informações que estavam naquele banco são substituídas pelas informações que estão no arquivo que será restaurado. Para resolver este problema, as alterações que forem feitas devem ser gravadas em scripts sql, e executadas depois do processo de restauração acontecer.
Até a próxima.

Diego Nogare - Graduado em Ciência da Computação e Pós-Graduado em Engenharia de Computação com ênfase em Desenvolvimento Web com .NET, Colaborador do Portal Linha de Código, co-Líder do grupo de usuários Codificando .NET, co-Líder dos Microsoft Student Partners [MSP] de São Paulo e Microsoft Most Valuable Professional [MVP] em SQL Server, possui certificações MCP e MCTS em SQL Server 2005, é palestrante em eventos da Microsoft, Codificando .NET e INETA BR, mantém o site: www.diegonogare.net.
- Representando dados em XML no SQL ServerSQL Server
- Diferenças entre SEQUENCES x IDENTITY no Microsoft SQL Server 2012SQL
- Utilizando FILETABLE no SQL Server 2012SQL Server
- NHibernate com o Delphi Prism: Acessando um Banco de Dados SQL ServerVisual Studio
- Novidades no SQL Server Codinome DenaliSQL Server
