
Gerência - Metodologias e Processos
MOF: Gerenciamento de Incidentes - SMF (Incident Management)
Iremos estudar neste artigo os processos sugeridos pela SMF Incident Management do MOF com o objetivo de entender como funciona o controle dos incidentes e solicitações recebidas pelo Service Desk.
por Cleber Farias MarquesObjetivo
|
Iremos estudar neste artigo os processos sugeridos pela SMF Incident Management do MOF com o objetivo de entender como funciona o controle dos incidentes e solicitações recebidas pelo Service Desk, boa leitura. |
Introdução
Obs.: Achei melhor deixar alguns termos em inglês mesmo porque na maioria das vezes iremos trabalhar com eles desta forma no mercado.
A SMF Incident Management - Gerenciamento de Incidentes, é responsável por restabelecer os serviços de operações o mais depressa possível para minimizar o impacto aos negócios da organização mantendo garantido os níveis de qualidade dos serviços e sua disponibilidade de acordo com os SLAs definidos. As tarefas estão entre estabelecer a normalidade dos serviços o quanto antes, minimizar o impacto dos incidentes na organização, garantir que os incidentes e as solicitações sejam processados constantemente e que nada é perdido ou esquecido, alocar a maior quantidade de recursos onde for mais necessário e buscar diminuir a quantidade de incidentes.
Os processos do Incident Management controlam todos os incidentes e solicitações abordadas pelo Service Desk, claro que seguindo a definição de incidente oferecida pela ITIL, que é: Um evento que foge do padrão no ambiente de operações de serviços, que pode causar uma interrupção ou redução na qualidade do serviço prestado. Geralmente os incidentes variam entre um serviço indisponível, problemas com aplicações, falha de hardware e infecções por vírus ou spywares.
Definições Importantes
Para entendermos melhor este artigo e a documentação oficial para esta SMF vamos conhecer algumas definições importantes que também são recomendadas pela Microsoft na própria documentação do MOF, lembrando também que mesmo algumas definições sendo as mesmas encontradas no mercado muitas delas são feitas com base nesta SMF.
Incident: Um evento que foge do padrão no ambiente de operações de serviços, que pode causar uma interrupção ou redução na qualidade do serviço prestado.
Initial Support Team: Equipe responsável pela primeira linha de suporte aos incidentes e solicitações de serviços, geralmente chamada de Suporte de Primeiro Nível. Tem como responsabilidade tentar solucionar os incidentes logo no primeiro contato, seguindo scripts e identificando as soluções conhecidas. Em muitas organizações o Service Desk atua como suporte de primeiro nível.
Known Error: Um incidente ou problema que já tem a causa raiz conhecida e possui um Workaround temporário ou uma alternativa de correção permanente identificada. Deverá permanecer como um Erro Conhecido até que alguma mudança no ambiente acabe com sua probabilidade de acontecer.
Major Incident: É um incidente que oferece um alto grau de impacto para o ambiente necessitando uma resposta mais rápida que o normal. Geralmente este tipo de incidente precisa de uma coordenação conjunta, escalonamento da gerência, mobilização de recursos adicionais e aumenta da comunicação.
Problem: A causa desconhecida de um ou mais incidentes. Um problema é identificado como uma causa raiz não solucionada.
Resolution Group: São grupos de especialistas que resolvem incidentes e solicitações que não foram solucionadas no primeiro nível. Em algumas empresas estas grupos são separados em níveis (como suporte segundo nível, terceiros e etc) ou em subáreas (como suporte a redes, a mainframe, banco de dados e etc), mas dependendo do tamanho da equipe de TI estes grupos podem ser formados de modo híbrido.
Service Desk: Um ponto único de contato para os clientes e usuários que precisam de um apoio técnico, o Service Desk coordena a maioria dos processos relacionados ao Incident Management e se relaciona com muitas outras SMFs.
Service Request: É uma solicitação de um novo serviço ou uma alteração em um existente. Nas organizações temos alguns tipos diferentes de Service Request, as mais comuns são Requests For Change (RFCs) e Requests For Information (RFIs).
Solution/Permanent Fix: São os meios possíveis identificados de se resolver um incidente ou problema que fornecem uma resolução permanente.
Workaround: São os meios possíveis identificados de se resolver um incidente em particular que permite o serviço voltar ao normal, porém não soluciona o problema de fato, não acabando com sua causa raiz.
Atividades do Processo
As atividades da SMF Incident Management podem ser representadas por um fluxo de processos que aborda as tarefas fundamentais necessárias para gerenciarmos incidentes com excelência, a seguir iremos conhecer as fases deste processo.
Detection, Self-Service, and Recording
Nesta primeira etapa deveremos realizar os três passos a seguir, acompanhe:
Detection: Para que um incidente seja tratado ele deve ser identificado e esta identificação geralmente é feita pelo usuário que sofre alguma eventualidade durante sua rotina de tarefas, lembrando que este usuário pode ser um cliente de qualquer área incluindo também o departamento de TI. Sendo assim aqui deveremos lidar com os processos de identificação de incidentes, recebendo os contatos dos usuários e garantindo que os incidentes estejam sendo tratados continuamente com o intuito de minimizar estas interrupções.
Self-Service: Este tipo de contato proporciona maior flexibilidade para os usuários na hora de procurar suporte. O contato com o Service Desk pode ser feito utilizando uma variedade de métodos como telefone, e-mail, aplicação web e etc. Porém independente da forma de contato deveremos controlar e garantir o nível de qualidade dos serviços prestados, levando em conta as diferenças entre os tipos de contato e fazer um planejamento cuidadoso para manter o trabalho do Service Desk sempre eficiente.
Recording: É importante registrar todos os contatos feitos com o Service Desk, pois com isso garantiremos que nenhuma solicitação ou incidente foi perdida ou esquecida. Este processo é importante para que possamos ter um histórico de registros e com isso identificar as tendências dos chamados, os tipos de solicitações mais freqüentes e assim por diante, tomando esta etapa como um apoio às estatísticas de gerenciamento.
Handling Service Requests
Nesta segunda etapa deveremos fazer o controle dos pedidos identificados e registrados, porém dependendo do tipo de pedido teremos que desenvolver ações diferentes, por exemplo, o controle de um incidente ou de uma solicitação terá passos diferentes entre sua identificação e registro de informações, mas ainda assim teremos também tarefas em comum como monitoramento dos incidentes e notificações aos usuários.
Classification and Initial Support
Nesta terceira etapa deveremos realizar os dois passos a seguir, acompanhe:
Classification: Aqui deveremos classificar o incidente da forma mais eficiente possível para utilizarmos a solução apropriada, neste processo de classificação deveremos categorizar e priorizar o incidente de acordo com as SLAs afetadas.
Initial Support: Será a atuação inicial do Service Desk para tentar solucionar o incidente visando a satisfação do cliente e sem necessariamente escalar a tarefa para alguma outra área de apoio. Isso é possível se o incidente já tiver um Erro Conhecido (Known Error) com detalhes sobre sua resolução ou um Workaround. É importante fazer sempre a relação de um incidente com um erro conhecido para manter atualizada esta lista de relacionamentos favorecendo futuras resoluções do mesmo tipo ou similar.
Investigation and Diagnosis
Quando um problema não pode ser solucionado pelo suporte inicial ele passa para esta fase, nesta quarta etapa deveremos diagnosticar o incidente escalando ele para um outro nível de solução, chamado de Resolver Group. O incidente será investigado por especialistas de outras equipes, SMFs e até da área de desenvolvimento se for necessário.
Major Incident Procedure
Esta quinta etapa acorrerá quando for identificado um incidente de grande impacto para o ambiente e que precise de uma solução imediata. Por este evento fugir da rotina ele deverá ser escalado para todas as partes envolvidas desde analistas, terceiros e até gerentes. Qualquer ação tomada deve ser comunicada a todos e ter aprovação antecipada.
Resolution and Recovery
Nesta sexta etapa deveremos executar as ações necessárias para resolver o incidente e retomar o estado do que não esta funcionando normalmente, garantindo que o incidente foi identificado e resolvido. Lembrando que as ações tomadas aqui (solução ou Workaround) deverão estar de acordo com o que foi planejado pela equipe das SMFs Change e Release Management.
Closure
Nesta sétima etapa deveremos fechar o chamado, teremos que verificar e informar ao usuário que abriu o chamado de que o mesmo foi solucionado. Entre as tarefas aqui teremos que garantir que os detalhes e a solução para o incidente foram registrados, categorizado e fechado no sistema de controle de incidentes, todas estas tarefas serão feitas pelos analistas do Service Desk.
Atenção: Vale lembrar que cada uma das etapas descritas acima oferece muito mais detalhes do que os que vimos aqui, porém detalhar o processo não é o intuito agora, com este artigo nós devemos entender basicamente como funcionam estes passos, mas futuramente iremos estudar estas recomendações na prática, para isso continuem acompanhando os artigos.
Logo abaixo podemos ver o diagrama que representa o fluxo citado acima, os processos neste caso seguem um ciclo iterativo, veja:
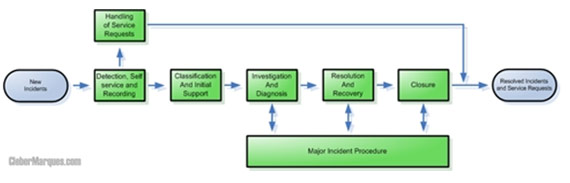
Figura 1 – Fluxo de processos da SMF Incident Management.
Com as novas tecnologias desenvolvidas pela Microsoft temos muito mais alternativas do que antes para nos apoiar na resolução dos passos descritos acima, um bom exemplo é o System Center, uma família de soluções de gerenciamento de TI que nos ajuda planejar, implantar, gerenciar e otimizar de forma pró-ativa nosso ambiente, temos também o SMS, MOM, ISA, Windows Server 2003 o 2008 entre outros, mas este é assunto para um próximo artigo.
Conclusão
Concluindo nosso artigo, pudemos ver que um Service Desk sem uma rotina de gerenciamento de incidentes não será tão eficiente quanto deve e os passos que vimos aqui devem ser tratados como um ciclo que busca ao mesmo tempo resolver um incidente, ou atender uma solicitação, e satisfazer o cliente, logo este incidente pode se tornar um problema se não resolvido e este será o assunto do nosso próximo artigo onde acompanharemos a rotina para gerenciarmos os problemas identificados no dia-a-dia, até lá, muito obrigado.

Cleber Farias Marques - Atua na área de TI desde 1997, é graduado em Análise e Desenvolvimento de Sistemas e Pós-graduando em Gestão de TI Aplicada aos Negócios. Possui certificações em ambiente de Infra-Estrutura Microsoft como MCP, MCDST, MCSA, MSFE e também ITIL Foundation, sendo o primeiro certificado MOF Foundation do Brasil. Idealista do projeto MOF Brasil (www.clebermarques.com) que tem como objetivo compartilhar as melhores práticas de ITSM.
- Singleton - Padrão de Projeto com Microsoft .NET C SharpC#
- Novidades no MVC 4.0Metodologias e Processos
- Vai abrir um negócio? - 10 dicas de como a tecnologia pode ser usada a seu favorMetodologias e Processos
- Regras de Negócio-Por que você deveria se importar com isso?Metodologias e Processos
- Governança, redução de custos e domínio da informação nas instituições financeiras: é possível?Network
