
Desenvolvimento - C#
Novidades na Linguagem C#
Este artigo mostra todas as novidades do C# em seqüência de uma maneira didática e com exemplos.
por Mauro Sant'AnnaIntrodução
O Microsoft Framework 2.0 trouxe diversas novidades nas linguagens de programação. A principal delas foi “Generics”, uma maneira escrever código onde os tipos são parametrizados. Isto vai além de funções normais, onde os valores é que são parametrizados. Os Generics permitem diversos novos recursos, como os tipos por valor (inteiros, por exemplo) que podem receber valor “null” e também coleções fortemente tipadas e bastante eficientes.
O suporte a Generics implicou em mudanças fortes nas camadas de mais baixo nível do .NET Framework, como novas instruções da linguagem IL e também a capacidade de gerar código em tempo de execução em alguns casos.
A nova versão do .NET Framework presente no Visual Studio 2008 traz evidentemente novas bibliotecas de classes com novas funcionalidades, como interface com usuário (WPF - Windows Presentation Foundation), comunicação (WCF – Windows Communication Foundation) e muitas outras novidades, algumas sem nomes grandiosos. No entanto, desta vez não houve grandes modificações nas camadas de baixo nível. Ou seja, o código IL é o mesmo da versão 2.0. Na verdade, as versões 3.0 e 3.5 do .NET Framework são essencialmente extensões do Framework 2.0 e não o substituem completamente. Seria então de esperar que não houvesse muitas novidades na linguagem, certo? Errado!
Na verdade, existem grandes modificações nas principais linguagens, C# e VB. E o interessante é que essas modificações existem apenas em nível do compilador das linguagens em si, quando os assemblies (DLL e EXE) são gerados, as instruções usadas são as mesmas que as antigas. Isto é importante, pois significa que as modificações são na verdade “truques” de compilação e muitas vezes restritas à própria classe ou mesmo apenas à própria função.
Inferência de tipos de variáveis
Considere o exemplo abaixo onde estamos declarando e inicializando uma variável na mesma linha de código:
int y = 20;
Somos obrigados a declarar o tipo, muito embora o compilador “saiba” que a variável deve ser inteira, pelo lado direito da expressão, que é um número inteiro. Efetivamente, salvo por algumas conversões automáticas, por exemplo de inteiro para ponto flutuante, se declararmos o tipo errado teremos um erro de compilação. Por exemplo:
string w = 10;
DateTime F = 10;
Ora, será que o compilador não poderia “saber” o tipo da variável automaticamente pelo tipo da expressão que está sendo atribuída a ela? Isso é exatamente o que a inferência de tipos de variáveis faz. Agora podemos escrever a expressão seguinte:
var x = 10;
Como estamos atribuindo um inteiro, o compilador sabe que a expressão “x” é do tipo inteiro. A expressão acima gera exatamente o mesmo código que a expressão a seguir:
int x = 10;
Uma vez compilado não dá para saber a diferença. Note que isto é muito diferente de declarar uma variável do tipo “object”. Com “object”, o tipo é decidido em tempo de execução e temos alguma perda de eficiência. Já com “var”, o tipo é conhecido em tempo de compilação e não existe nenhuma perda de eficiência em relação a declarar um inteiro ou outro tipo especificamente.
Um detalhe: este recurso só está disponível para variáveis locais, ou seja, as declaradas dentro de um método. Você não pode usá-lo em variáveis de classe.
Object Initializers
Suponha que você tem uma classe com uma série de propriedades públicas que você queira inicializar, por exemplo:
class Pessoa
{
public Pessoa()
{
FNome = string.Empty;
FSobrenome = string.Empty;
}
string FNome;
public string Nome
{
get { return FNome; }
set { FNome = value; }
}
string FSobrenome;
public string Sobrenome
{
get { return FSobrenome; }
set { FSobrenome = value; }
}
}
Este seriao código de inicialização:
var P0 = new Pessoa();
P0.Nome = "Mauro";
P0.Sobrenome = "Sant"Anna";
É claro que podemos declarar um construtor que aceite um nome e um sobrenome como argumentos:
public Pessoa(string Nome, string Sobrenome)
{
this.FNome = Nome;
this.FSobrenome = Sobrenome;
}
E chamar assim:
var P1 = new Pessoa("Mauro", "Sant"Anna");
Mas ainda assim dá um certo trabalho. O C# 3.0 permite a sintaxe abaixo sem ter que criar o construtor específico:
var P1 = new Pessoa { Nome = "Mauro", Sobrenome = "Sant"Anna" };
O código acima gera exatamente o mesmo que:
var P0 = new Pessoa();
P0.Nome = "Mauro";
P0.Sobrenome = "Sant"Anna";
Collection Initializers
Os arrays do C# permitem uma inicialização bastante fácil, como por exemplo:
char [] Vogais3 = { "A", "E", "I", "O", "U" };
Já se tivermos uma coleção, temos que iniciar os elementos um por um, como no exemplo abaixo:
List<char> Vogais1 = new List<char>();
Vogais1.Add("A");
Vogais1.Add("E");
Vogais1.Add("I");
Vogais1.Add("O");
Vogais1.Add("U");
Seria interessante se pudessemos inicializar as coleções da mesma maneira que os arrays. Bem, isso agora é possível com a sintaxe seguinte:
var Vogais2 = new List<char> { "A", "E", "I", "O", "U" };
O código acima gera exatamente o mesmo código que o anterior, mas é mais conveniente de escrever.
Autogenerated Properties
É comum criar classes nas quais armazenamos dados em variáveis e colocamos propriedades de acesso, como na classe Pessoa do exemplo anterior. Isto significa que escrevemos um monte de código “braçal”, além de ter que inventar um nome para a variável diferente da propriedade - eu costumo preceder com a letra “F”, como no exemplo acima.
O novo recurso de “propriedades autogeradas” permite que declaremos apenas a propriedade de uma maneira bastante simplificada e a variável de instância é declarada automaticamente, como no exemplo abaixo:
public class Pessoa {
public string Nome {get; private set; }
public string Sobrenome { get; private set; }
public Pessoa(string Nome, string Sobrenome)
{
this.Nome = Nome;
this.Sobrenome = Sobrenome;
}
}
Note que não é mais possível acessar diretamente a variável; isto deve ser feito obrigatoriamente através da propriedade. No exemplo acima, a atribuição é “private” exatamente para evitar que os dados possam ser atualizados diretamente.
Veja a classe gerada com a ferramenta ILDASM:

Observe as variáveis criadas automaticamente.
Anonymous Types
Até a versão 2.0 do Framework, todos os tipos precisavam ser explicitamente declarados antes de utilizados. Agora, o compilador pode declara automaticamente alguns tipos para nós.
Considere a classe a seguir
class Pessoa {
public Pessoa(string Nome, string Sobrenome)
{
this.FNome = Nome;
this.FSobrenome = Sobrenome;
}
string FNome;
public string Nome
{
get { return FNome; }
}
string FSobrenome;
public string Sobrenome
{
get { return FSobrenome; }
}
public override int GetHashCode()
{
return Nome.GetHashCode() ^ Sobrenome.GetHashCode();
}
public override bool Equals(object obj)
{
Pessoa P = (Pessoa)obj;
return ((P.Nome == Nome) && (P.Sobrenome == Sobrenome));
}
public override string ToString()
{
return string.Format("Nome: {0} Sobrenome: {1}", Nome, Sobrenome);
}
}
Esta classe armazena dados de uma pessoa, mas especificamente nome e sobrenome. Ela contém campos para armazenar os dados, um construtor para inicializar e propriedades de leitura. Além disso, sobrecarrega três métodos: ToString(), Equals() e GetHashCode(). Estes três últimos não são particularmente importantes, eles estão aí mais para deixar a classe completa.
Podemos utilizar a classe da seguinte forma:
var P1 = new Pessoa("Mauro", "Sant"Anna");
Console.WriteLine(string.Format("{0} {1} {2}", P1.GetType().ToString(), P1.Nome, P1.Sobrenome));
Pode ser que desejemos deixar os tipos de Nome e Sobrenome como sendo genéricos, assim podemos definir seus tipos exatos em tempo de execução. Neste caso, a classe ficaria assim:
class GenericPessoa<T1, T2>
{
public GenericPessoa(T1 Nome, T2 Sobrenome)
{
this.FNome = Nome;
this.FSobrenome = Sobrenome;
}
T1 FNome;
public T1 Nome
{
get { return FNome; }
}
T2 FSobrenome;
public T2 Sobrenome
{
get { return FSobrenome; }
}
public override int GetHashCode()
{
return Nome.GetHashCode() ^ Sobrenome.GetHashCode();
}
public override bool Equals(object obj)
{
GenericPessoa<T1, T2> P = (GenericPessoa<T1, T2>)obj;
return ((P.Nome.Equals(Nome)) && (P.Sobrenome.Equals(Sobrenome)));
}
public override string ToString()
{
return string.Format("Nome: {0} Sobrenome: {1}", Nome, Sobrenome);
}
}
Poderíamos usar desta forma:
var P2 = new GenericPessoa<string, string>("Mauro", "Sant"Anna");
Console.WriteLine(string.Format("{0} {1} {2}", P2.GetType().ToString(), P2.Nome, P2.Sobrenome));
Não existe nada de errado com o código acima. A questão é que este tipo de classes para conter valores é bastante comum e escrevê-las demanda certo trabalho braçal.
O compilador C# 3.0 pode agora declarar classes como a acima automaticamente apenas ao se declarar e inicializar uma variável da seguinte forma:
var P3 = new { Nome = "Mauro", Sobrenome = "Sant"Anna" };
O compilador irá criar uma classe real, visível com ferramentas como debugger e decompiladores. Esta classe é virtualmente idêntica à classe GenericPessoa criada anteriormente, mas não precisamos ter tido nenhum trabalho para isso!
Efetivamente, o decompilador ILDASM, fornecido com o Visual Studio permite examinar as classes e ver como elas são semelhantes.
Estas são as classes explícitas:
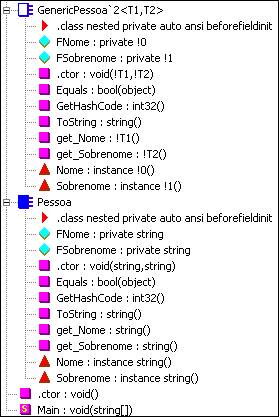
Esta é a classe anônima. Note a semelhança com a classe acima definida com Generics, a não ser por alguns atributos diferentes:

Extension Methods
Um método de instância nada mais é que um método “static” que aceita um parâmetro escondido, o “this”. Podemos criar em uma classe um método “static” que aceita uma instância da própria classe, mas isso não faz muito sentido; é melhor criar um método de instância logo de uma vez.
Caso desejemos em uma classe “B” manipular uma instância de uma classe “A”, podemos passar uma instância de A como parâmetro de algum método de B. Se este método de B não precisar acessar nada de B, ele pode muito bem ser estático.
Considere o exemplo abaixo:
class Numero
{
public Numero(int N)
{
FX = N;
}
int FX;
public int X
{
get { return FX; }
set { FX = value; }
}
public override string ToString()
{
return FX.ToString();
}
}
static class Extensora
{
public static void Dobro(Numero N)
{
N.X = 2 * N.X;
}
}
O método “Dobro” da classe Extensora manipula a classe Numero. Podemos usar o seguinte código:
Numero N = new Numero(10);
Extensora.Dobro(N);
O método “Dobro” pertence à classe “Extensora”, mas ele na verdade manipula instâncias da classe “Numero”. Seria interessante poder usar a sintaxe abaixo:
Numero N = new Numero(10);
N.Dobro();
É exatamente isso que um “extension method” permite. Ele é um método declarado em outra classe, mas que funciona como um método da própria classe. Ele é declarado em uma classe estática e a única diferença é o uso da palavra reservada “this” como mostrado abaixo:
static class Extensora
{
public static void Dobro(this Numero N)
{
N.X = 2 * N.X;
}
}
O Visual Studio reconhece os “extension methods” e apesar de listá-los na classe estendida, eles aparecem com uma seta azul indicando este fato:
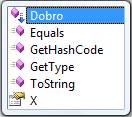
Lambda Expressions
Esta novidade tem um nome meio esquisito, que parece vindo de um filme de ficção científica. Aliado a uma sintaxe meio peculiar, ele torna-se um recurso meio difícil de entender. Mas não é algo tão complicado, pois se parece mais como um “delegate metido à besta”.
Muitas vezes no desenvolvimento de software precisamos de algum mecanismo de “calback”, que permita que um código chame a outro através de algum tipo de ponteiro de função.
No .NET Framework, este mecanismo existe desde a versão 1.0 e chama-se “delegates”. Veja por exemplo o seguinte código:
delegate double Operacao(double x, double y);
static double Soma(double x, double y)
{
return x + y;
}
static double Produto(double x, double y)
{
return x * y;
}
private static void UsaDelegate()
{
Operacao F;
F = Soma;
Console.WriteLine(F(10, 30));
F = Produto;
Console.WriteLine(F(10, 30));
}
O delegate é um tipo que permite por exemplo declarar variáveis como “F” acima. À esta variável podemos atribuir o endereço de uma ou outra função e decidir isso em tempo de execução. O código funciona, mas não é muito conciso.
No Framework 2.0 temos os “anonymous methods”, que permite associar um bloco de código a um delegate sem precisar declarar funções explicitamente. O código acima poderia ser escrito da seguinte forma:
delegate double Operacao(double x, double y);
private static void UsaAnonymousMethod()
{
Operacao F;
F = delegate(double x, double y)
{
return x + y;
};
Console.WriteLine(F(10, 30));
F = delegate(double x, double y)
{
return x * y;
};
Console.WriteLine(F(10, 30));
}
O código acima quando compilado acaba gerando dois métodos, de forma muito semelhante ao exemplo anterior.
Note que não precisamos mais os corpos das funções “Soma” e “Produto”. Isto é particularmente útil em métodos com pouco código que não serão chamados de outros lugares. Já no C# 3.0, podemos usar uma sintaxe ainda mais simples:
private static void UsaLambda()
{
Func<double, double, double> F;
F = (x, y) => x + y;
Console.WriteLine(F(10, 30));
F = (x, y) => x * y;
Console.WriteLine(F(10, 30));
}
O código acima acaba geando mais ou menos o mesmo código que o anterior, mas o fonte é mais conciso.
Note o seguinte:
· Func<double, double, double> é semelhante a declarar um delegate que aceita dois double e retorna um “double” (o tipo mais à direita é o tipo de retorno);
· => significa “vai para”
· “(x, y) =>” corresponde à declaração de um método anônimo que aceita dois valores;
· “x + y” corresponde ao corpo da função;
· Caso a expressão do lado esquerdo de => contenha apenas um valor, os parênteses podem ser omitidos.
Um lambda é uma maneira muito conveniente de especificar um “callback”. Por exemplo, suponha que queremos varrer todos os elementos de uma lista de strings e separar os elementos que atendem a certo critério. Podemos definir um método que aceita um lambda com o critério de seleção:
static List<string> Seleciona(List<string> Lista, Func<string, bool> F) {
List<string> Result = new List<string>();
foreach (string S in Lista)
{
if (F(S)) {
Result.Add(S);
}
}
return Result;
}
Func<string, bool> corresponde a um lambda que aceita uma string e retorna um “bool” indicado se o elemento deve ser selecionado. Podemos chamar a função acima da seguinte forma:
List<string> Lista = new List<string> {"Maria", "Camila", "Mariana", "Carla"};
List<string> Resultado = Seleciona(Lista, b => b[0] == "C");
Note que o critério (no caso a primeira letra ser ‘C’ é especificado na chamada à função. É como se o código fosse um parâmetro da função. No fim das contas, o efeito do lambda é estamos sob certos aspectos “tratando funções como dados”, um mecanismo presente em linguagens “funcionais” como LISP. Não estou aqui afirmando que o C# tem a mesma expressividade que linguagens puramente funcionais, mas o C# “tomou emprestado” um mecanismo delas.
Em resumo, uma expressão lambda é uma forma simplificada de um método anônimo e pode ser usada em praticamente qualquer lugar em que um delegate seria usado. Além disso, um lambda pode referir-se a uma “Expression Tree” (veja a seguir).
Expression Tree
Uma “expression tree” ou “árvore de expressão” é semelhante às expressões que podemos definir em tempo de compilação, mas no caso das “expresion trees”, elas são definidas em tempo de execução.
Estas expressões podem ser depois compiladas e chamadas a partir de nosso código. O exemplo a seguir cria uma expressão que soma dois números, compila e invoca a expressão:
ParameterExpression x = Expression.Parameter(typeof(double), "x");
ParameterExpression y = Expression.Parameter(typeof(double), "y");
Expression body = Expression.Add(x, y);
Expression<Func<double, double, double>> Exp = Expression.Lambda<Func<double, double, double>>(body, x, y);
Console.WriteLine(Exp);
Func<double, double, double> F = Exp.Compile();
Console.WriteLine(F(10, 40));
Ou seja, os “lambdas” são até mais expressivos que os delegates, pois temos uma maneira fácil e bem documentada de criar expressões em tempo de execução, compilá-las e executálas.
De uma certa forma isso era possível anteriormente, mas deveríamos criar um assembly e chamá-lo com remoting, um trabalho bem maior.
LINQ
O objetivo principal do LINQ é aproximar dois mundos presentes no desenvolvimento de software que são relativamente separados: o mundo das linguagens de programação e o dos bancos de dados, especialmente os bancos de dados relacionais.
Os principais problemas endereçados pelo LINQ são os seguintes:
· As consultas de banco de dados relacionais são baseadas em strings, que são quase como “corpos estranhos” em relação ao resto dos elementos das linguagens de programação. A manipulação de strings é sujeita não só a erros, usualmente descobertos apenas em tempo de execução, como também a um grave problema de segurança chamado “injeção de SQL”.
· Os conjuntos de resultados retornados pelas consultas voltam em um formato que deve ser traduzido de alguma forma para s linguagem de alto nível.
O LINQ consolida as novidades discutidas anteriormente de forma a facilitar o acesso a banco de dados, permitindo expressões semelhantes às linguagens de quarta geração, mas sem abandonar as linguagens OOP tradicionais. Com o LINQ podemos efetuar uma consulta em uma base de dados com um comando semelhante ao seguinte:
IEnumerable<string> query =
from s in Nomes
where s.StartsWith("A")
orderby s
select s.ToUpper();
Um exemplo simples
Suponha que tenhamos a seguinte classe:
class Linq1
{
static string[] Nomes = { "Antonio", "Amanda", "Bruno", "Frederico", "Alberto", "Jorge", "Mauricio", "Ademar" };
static void Mostra(IEnumerable<string> query)
{
foreach (string item in query)
Console.WriteLine(item);
}
private static void Exp1()
{
Console.WriteLine(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> Exp1");
IEnumerable<string> query = Nomes.Where(s => s.StartsWith("A"));
Mostra(query);
}
static void Main()
{
Exp1();
}
}
Note que no método Exp1 estamos usando um Extension Method chamado “Where” para o qual passamos a expressão lambda “s => s.StartsWith(“A”)” para especificar o critério de seleção.
Podemos adicionar ao resultado uma chamada a outro Extension Method, “OrderBy” passando a expressão lambda “s => s” de forma a ordenar o resultado:
private static void Exp2()
{
Console.WriteLine(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> Exp2");
IEnumerable<string> query = Nomes.Where(s => s.StartsWith("A"));
query = query.OrderBy(s => s);
Mostra(query);
}
Adicionaremos outra chamada a um Extension Method que dirá o que selecionamos, no caso os dados convertidos para maiúsculo:
private static void Exp3()
{
Console.WriteLine(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> Exp3");
IEnumerable<string> query = Nomes.Where(s => s.StartsWith("A"));
query = query.OrderBy(s => s);
query = query.Select(s => s.ToUpper());
Mostra(query);
}
Evidentemente podemos colocar tudo em uma única linha de código:
private static void Exp4()
{
Console.WriteLine(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> Exp4");
IEnumerable<string> query = Nomes.Where(s => s.StartsWith("A")).OrderBy(s => s).Select(s => s.ToUpper());
Mostra(query);
}
O C# 3.0 tem uma novidade chamada “query expressions” que permite escrever a linha de código acima de uma forma mais elegante, usando novos operadores que mapeiam para os extension methods acima. Com estes novos operadores, o código fica assim:
private static void Exp5()
{
Console.WriteLine(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> Exp5");
IEnumerable<string> query =
from s in Nomes
where s.StartsWith("A")
orderby s
select s.ToUpper();
Mostra(query);
}
LINQ to SQL
Evidentemente a maior parte dos dados estará em bancos de dados SQL. Portanto, é interessante termos uma maneira de mapear a expressão LINQ para uma chamada SQL submetida a um servidor.
Para isso precisamos inicialmente definir uma classe que armazenará os dados retornados pela query. Esta classe deve ter um campo para cada coluna da query e atributos adequados, como por exemplo:
[Table(Name = "Products")]
public class Products
{
[Column]
public int ProductID { get; set; }
[Column]
public string ProductName { get; set; }
[Column]
public int? CategoryID { get; set; }
}
Depois precisamos criar um “DataContext”, que basicamente contém uma string de conexão SQL para um SQL Server. Depois disso chamamos o método GetTable que retorna uma referência a uma Tabela que será usada posteriormente na query LINQ, como mostrado a seguir:
static void Main()
{
DataContext context =
new DataContext(@"Initial Catalog=Northwind;Integrated Security=sspi");
Table<Products> Prods = context.GetTable<Products>();
var q = from c in Prods
where c.CategoryID == 1
select c;
foreach (Products P in q)
{
Console.WriteLine(P.ProductName);
}
}
A criação do comando SQL é feita dinamicamente e a query é executada apenas no momento em que os dados são lidos na chamada a foreach.
A classe DataContext é específica para o Microsoft SQL Server, mas já foram anunciadas classes similares para outros bancos de dados como Oracle, Postgres e MySSQL.
Conclusão
O uso do LINQ permite a criação de código de maneira mais fácil que o correspondente código ADO.NET.e representa sem dúvida uma grande inovação em recusros em uma linguagem de programação de uso amplo.
Mauro Sant’Anna (mauro@mas.com.br) ministra terinamentos na MAS Informática (www.mas.com.br).

