
Banco de Dados - SQL Server
Melhoramentos no T-SQL para SQL Server 2005 - ROW_NUMBER, RANK, DENSE_RANK e NTILE
Veremos neste artigo as quatro novas functions que foram criadas para nos ajudar a criar querys para análise de dados mais eficientes e com mais facilidade.
por Eugênio SpoltiEstamos de volta com a nossa série sobre os melhoramentos do T-SQL na nova versão do SQL Server 2005. Veremos neste artigo as quatro novas functions que foram criadas para nos ajudar a criar querys para análise de dados mais eficientes e com mais facilidade.
As quatro novas funções são: ROW_NUMBER, RANK, DENSE_RANK e NTILE. A sintaxe básica de qualquer uma delas é a seguinte:
<function_name>() OVER( [PARTITION BY <partition_by_list>] ORDER BY <order_by_list>)
Antes de começarmos a ver as funções vamo a tabela e aos dados que iremos utilizar como exemplo. Utilizaremos como exemplo uma tabela que conterá as vendas de telemarketing por vendedor e tipo de produto, além da quantidade vendida. Um exemplo bem simples mas que poderemos utilizar para rankear os vendedores de várias maneiras. Segue abaixo a criação e alguns dados para nossos testes.
Create table Analise_Vendas ( Vendedor char(30), Produto Char(30),
Quantidade numeric(15,4), Telefonemas integer )
insert into Analise_Vendas values ("João","Geladeira",5,15)
insert into Analise_Vendas values ("Jonas","Geladeira",2,13)
insert into Analise_Vendas values ("Rafael","Televisão",6,9)
insert into Analise_Vendas values ("Rafael","Geladeira",1,6)
insert into Analise_Vendas values ("João","Televisão",2,8)
insert into Analise_Vendas values ("Jonas","Bicicleta",7,11)
insert into Analise_Vendas values ("Rafael","Bicicleta",3,9)
insert into Analise_Vendas values ("Jonas","Roupeiro",4,9)
insert into Analise_Vendas values ("João","Computador",9,25)
insert into Analise_Vendas values ("Rafael","Computador",1,5)
insert into Analise_Vendas values ("João","Fogão",3,6)
insert into Analise_Vendas values ("Rafael","Fogão",6,8)
insert into Analise_Vendas values ("Jonas","Cama",2,3)
insert into Analise_Vendas values ("João","Cama",5,9)
ROW_NUMBER
Esta função irá nos prover um número sequencial e inteiro para cada linha que o nossa query possuir.
select ROW_NUMBER() over ( ORDER BY Quantidade Desc ) as Numero, Vendedor, Produto, Quantidade, Telefonemas from Analise_Vendas
Teremos o seguinte resultado:
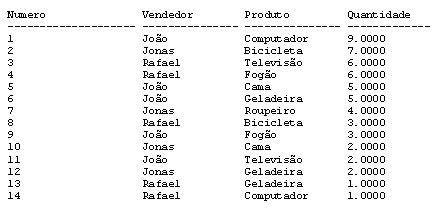
Somente conseguiriá-mos este resultado na Versão 2000 utilizando uma técnica com sub-querys.
select ( SELECT COUNT(*) from Analise_Vendas V2 where V2.Quantidade> V.Quantidade or ( V2.Quantidade = V.Quantidade and V2.Telefonemas> V.Telefonemas )) + 1 As Numero , V.Vendedor, V.Produto , V.Quantidade, V.Telefonemas from Analise_Vendas V order by Quantidade Desc , Telefonemas Desc
Como podemos no comando acima, a query fica muito mais complexa de ser entendida. Poderia-mos ainda acrescentar na nossa query a outra opção da sintaxe básica que se chama PARTITION BY, que funciona mais ou menos como o group by, definindo por qual critério nosso ROW_NUMBER deverá ser ressetado.
select ROW_NUMBER() over ( PARTITION BY Produto ORDER BY Quantidade Desc ) as Numero, Vendedor, Produto, Quantidade from Analise_Vendas
Teremos o seguinte resultado:
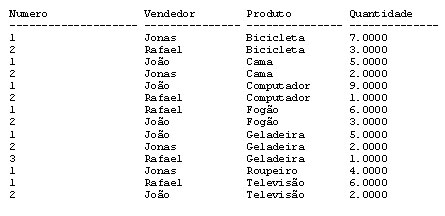
Podemos notar que a diferença para nosso select anterior é que agora nossa coluna Número reinicia a contagem a cada novo produto além de ordenar por Quantidade.
Uma outra ídéia para utlizar esta função seria para criar uma páginação para nossa query, podendo utiliza-lá em alguma página na Web.
DECLARE @NumeroDaPagina AS INT, @TamanhoDaPagina AS INT SET @NumeroDaPagina = 2 SET @TamanhoDaPagina = 5 SELECT * FROM (SELECT ROW_NUMBER() OVER(ORDER BY Quantidade DESC ) AS Numero, Vendedor, Produto , Quantidade, Telefonemas FROM Analise_Vendas) AS V WHERE Numero BETWEEN (@NumeroDaPagina-1)* @TamanhoDaPagina+1 AND @NumeroDaPagina*@TamanhoDaPagina ORDER BY Quantidade DESC, Telefonemas
Teremos o seguinte resultado:

RANK() e DENSE_RANK()
O funcionamento destas funções é muito parecido com o ROW_NUMBER, elas também irão nos prover com um número sequencial e inteiro. A diferença principal é que RANK e DENSE_RANK atribuem o mesmo valor para as colunas que possuem o mesmo valor dentro da ordem qe foi estabelecida. Verificando o exemplo abaixo ficará mais claro:
SELECT Vendedor, Produto, Quantidade, ROW_NUMBER() OVER(ORDER BY Quantidade DESC) AS Numero, RANK() OVER(ORDER BY Quantidade DESC) AS Rank, DENSE_RANK() OVER(ORDER BY Quantidade DESC) AS DenseRank FROM Analise_Vendas ORDER BY Quantidade DESC
Teremos o seguinte resultado:
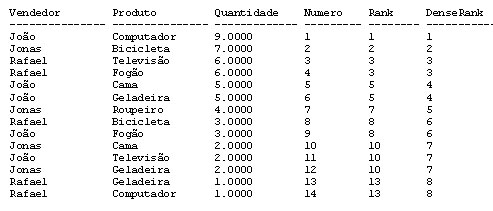
Vamos então analisar os resultados, a função RANK() nos dará o número sequencial, mas irá repetir o valor para os registros que possuirem mesmo valor para a coluna que estamos analisando e pulando a sequência, já a função DENSE_RANK() também irá repetir o sequêncial para as colunas que tiverem o mesmo valor, mas seguirá o sequêncial na ordem correta.
NTILE
Esta função nos permite separar o resultado de uma query em um determinado número de grupos de acordo com uma ordem.
SELECT Vendedor, Produto, Quantidade, ROW_NUMBER() OVER(ORDER BY Quantidade DESC) AS Numero, NTILE(3) OVER(ORDER BY Quantidade DESC) as Grupo FROM Analise_Vendas ORDER BY Quantidade DESC
Teremos o seguinte resultado:
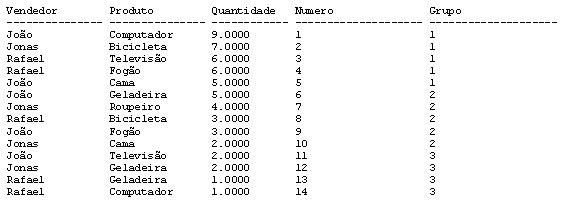
Como podemos ver na coluna grupo, separamos os registros em três grupos, utilizando a seguinte fórmula NumeroDeRegistros / NumerodeGrupos , sendo que no máximo o primeiro grupo poderá possuir um registro a mais.
Agora só vocês colocarem a mão na massa e criar os seus próprios testes para estas novas funções do SQL Server 2005.
Até a próxima
Eugênio Spolti

- Representando dados em XML no SQL ServerSQL Server
- Diferenças entre SEQUENCES x IDENTITY no Microsoft SQL Server 2012SQL
- Utilizando FILETABLE no SQL Server 2012SQL Server
- NHibernate com o Delphi Prism: Acessando um Banco de Dados SQL ServerVisual Studio
- Novidades no SQL Server Codinome DenaliSQL Server
