
Desenvolvimento - SQL
Tunning Index com o DTA
Veja neste artigo a utilização do DTA (DataBase Engine Tuning Advisor) como a ferramenta principal para tuning de indexes criados em tabelas dentro de uma base de dados.
por Marcos Leandro RosaEste artigo foca a utilização do DTA (DataBase Engine Tuning Advisor) como a ferramenta principal para tuning de indexes criados em tabelas dentro de uma base de dados. Mas antes de iniciar a leitura sobre o DTA, é crucial que todos tenham em mente o quanto a informação foi valorizada nos tempos atuais, e, como se tornou vital para estratégias empresariais. Para se ter uma noção exata do quanto a informação foi valorizada nos últimos tempos, basta voltar pouco antes dos anos 50, quando empresas dependiam de muitas pessoas trabalhando no armazenamento de documentos em papéis, e comparar com os dias atuais.
Da mesma maneira que tudo se evoluiu, os problemas e a complexidade das coisas também evoluíram e para tanto, renovação e readaptação são duas palavras constantes na vida de todo profissional de TI; Nós como DBA’s temos que estar aptos a conhecer novas formas de trabalhar todos os dias, e é em função disto que este artigo foi escrito.
Como o artigo foca o tuning de base de dados e indica a criação de índices como um primeiro passo para o ganho de performance, vamos primeiramente conhecer o Profiler do SQL Server 2005 para, somente depois, iniciarmos o tuning de uma base.
Entendendo o Profiler do SQL Server 2005
Utilizamos o Profiler quando queremos ver todas as transações que estão ocorrendo dentro de uma determinada base de dados. O artigo foca a utilização do profiler nesta tarefa, pois é uma ferramenta prática de se trabalhar e que nos poupa muito trabalho.
No dia-a-dia, ao analisar a performance de uma base, é possível se deparar com muitos fatores que influenciam na agilidade do nosso banco, por exemplo; Falta de index em consultas, Consultas que não utilizam índices, Hardware, Rede entre outros. Com o Profiler, tudo isso pode ser percebido com passos bastante simples.
O Profiler é uma ferramenta gráfica instalada junto com o SQL Server (neste caso com o 2005) que possibilita capturarmos informações tais como:
1- Login ou logout de um usuário na base de dados;
2- RPC completadas – Indica que a chamada a uma stored procedure remota foi completada;
3- T-SQL batch iniciado e completado – Indica que um batch de comandos T-SQL foi completado ou está iniciando;
4- Conexões existentes – Demonstra conexões existentes assim que o trace é iniciado.
Como o objetivo deste artigo não é ensinar a trabalhar com o profiler, mas sim com o DTA, vamos apenas conhecer como abrir, executar um trace simples e salvar este trace em arquivo. Para isso, no SQL Server Management Studio (SSMS), abra o Profiler acessando o menu Tools à SQL Server Profiler (veja aFigura 1).
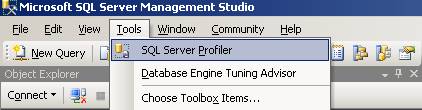
Figura 1. Acessando o Profiler de dentro do SSMS
Ao abrir a tela do Profiler, é importante conhecer o nome do servidor que você está querendo acessar, pois somente assim será possível a criação de um novo trace. Agora, para criar um novo trace, acesse o menu File à New Trace e depois conecte-se ao servidor onde você deseja que o trace seja executado.
Quando a conexão for estabelecida, a janela que será mostrada na tela (Figura 2) deverá ser configurada.
 Figura
2. Configurando a tela do trace
Figura
2. Configurando a tela do trace
No campo denominado Trace name coloque o nome do trace, neste exemplo foi utilizado “ExSQLMagazine”, mas este nome pode ser de sua preferência, desde que seja um nome lógico para o cenário no qual você está trabalhando. O artigo foca de forma superficial a utilização do Profiler, portanto veremos apenas recursos básicos do trace. Em seguida, acesse o campo denominado “Use the Template” e utilize o template “TSQL_Duration”, e logo após selecione a opção “Save to file” para salvar o trace em um arquivo com a extensão “trc”. Se você seguiu todos os passos corretamente, sua tela deverá estar configurada da mesma maneira que a Figura 3.
Agora basta clicar no botão “Run” que o trace iniciará. Na configuração anterior, existe a guia “Events Selection” (Figura4), onde podemos configurar várias opções de traces, e os pontos que cada evento pode afetar. Para entender melhor e conhecer os inúmeros eventos que podemos realizar, busque no books online o assunto SQL Server Profiler.
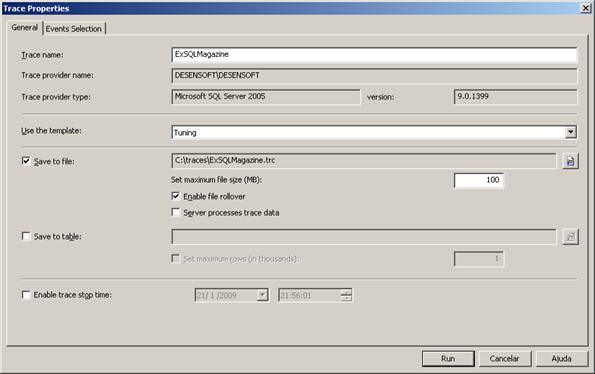
Figura 3. Tela Configurada Para Realização do Trace
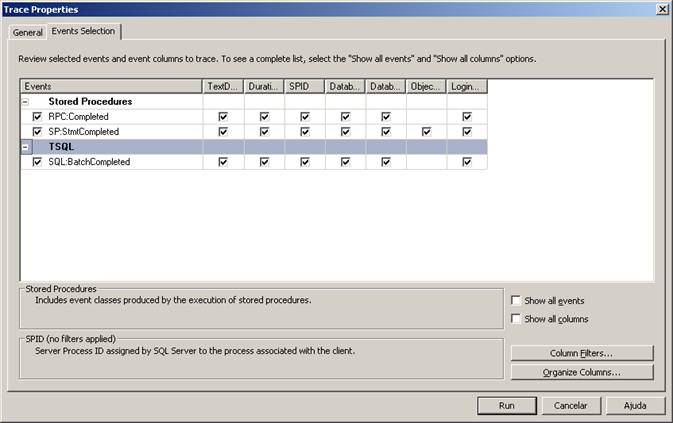
Figura 4. Outras Opções de Trace e detalhamento de notificações para cada evento.
Se apenas iniciarmos o trace e nada ocorrer dentro da base de dados, o mesmo não terá validade alguma. Portanto, para efeito de testes, execute a T-SQL proposta na Listagem 1 para realizarmos alguns exercícios com o âmbito de fixarmos o entendimento sobre o Profiler.
Vamos supor que queremos saber dos clientes de número 270 a 280, quantos compraram acima de 10 itens na data superior a 31 de Dezembro de 2001, veja na listagem 1, que a consulta é complexa, pois conta com várias junções com outras tabelas, portanto, este é um bom exemplo para utilizarmos e realizar a análise do profiler e futuramente no DTA.
Listagem 1. Código TSQL para realização do teste
SELECT Production.Product.ProductID, Production.Product.Name AS ProductName, Sales.SalesOrderDetail.SalesOrderID, Sales.SalesOrderDetail.OrderQty,
Sales.SalesOrderHeader.OrderDate, Sales.SalesTerritory.Name AS TerritoryName, Sales.SalesTerritory.CountryRegionCode,
Sales.SalesPerson.SalesPersonID, Person.Contact.FirstName, Person.Contact.Phone
FROM Sales.SalesPerson INNER JOIN Sales.SalesTerritory INNER JOIN
Sales.Customer ON Sales.SalesTerritory.TerritoryID = Sales.Customer.TerritoryID AND
Sales.SalesTerritory.TerritoryID = Sales.Customer.TerritoryID AND Sales.SalesTerritory.TerritoryID = Sales.Customer.TerritoryID AND
Sales.SalesTerritory.TerritoryID = Sales.Customer.TerritoryID ON Sales.SalesPerson.TerritoryID = Sales.SalesTerritory.TerritoryID AND
Sales.SalesPerson.TerritoryID = Sales.SalesTerritory.TerritoryID AND Sales.SalesPerson.TerritoryID = Sales.SalesTerritory.TerritoryID AND
Sales.SalesPerson.TerritoryID = Sales.SalesTerritory.TerritoryID AND Sales.SalesPerson.TerritoryID = Sales.SalesTerritory.TerritoryID INNER JOIN Sales.SalesOrderHeader ON Sales.SalesPerson.SalesPersonID = Sales.SalesOrderHeader.SalesPersonID AND
Sales.SalesTerritory.TerritoryID = Sales.SalesOrderHeader.TerritoryID AND
Sales.Customer.CustomerID = Sales.SalesOrderHeader.CustomerID INNER JOIN
Production.Product INNER JOIN Production.ProductModel ON Production.Product.ProductModelID = Production.ProductModel.ProductModelID INNER JOIN
Sales.SalesOrderDetail ON Production.Product.ProductID = Sales.SalesOrderDetail.ProductID ON
Sales.SalesOrderHeader.SalesOrderID = Sales.SalesOrderDetail.SalesOrderID AND Sales.SalesOrderHeader.SalesOrderID = Sales.SalesOrderDetail.SalesOrderID AND
Sales.SalesOrderHeader.SalesOrderID = Sales.SalesOrderDetail.SalesOrderID AND Sales.SalesOrderHeader.SalesOrderID = Sales.SalesOrderDetail.SalesOrderID AND
Sales.SalesOrderHeader.SalesOrderID = Sales.SalesOrderDetail.SalesOrderID INNER JOIN Person.Contact ON Sales.SalesOrderHeader.ContactID = Person.Contact.ContactID AND
Sales.SalesOrderHeader.ContactID = Person.Contact.ContactID AND Sales.SalesOrderHeader.ContactID = Person.Contact.ContactID AND
Sales.SalesOrderHeader.ContactID = Person.Contact.ContactID AND Sales.SalesOrderHeader.ContactID = Person.Contact.ContactID AND
Sales.SalesOrderHeader.ContactID = Person.Contact.ContactID INNER JOIN
Sales.CustomerAddress ON Sales.Customer.CustomerID = Sales.CustomerAddress.CustomerID
WHERE (Sales.SalesPerson.SalesPersonID BETWEEN 270 AND 280)
AND (Sales.SalesOrderDetail.OrderQty > 10)
AND (Sales.SalesOrderHeader.OrderDate >
CONVERT(DATETIME, '2001-12-31 00:00:00', 102))
Para realizar a consulta da Listagem 1 é necessário que você tenha a base de dados AdventureWorks (encontrada em http://www.microsoft.com/downloads/details.aspx?familyid=e719ecf7-9f46-4312-af89-6ad8702e4e6e&displaylang=en ) importada para a instância que você está realizando o trace. Logo após, abra um novo arquivo de script pelo SSMS e digite a consulta da Listagem 1. Rode a consulta e verifique no trace quantos milissegundos a consulta levou até ser finalizada. Após consultar, rode-a novamente e verifique na nova linha do trace quantos segundos a consulta durou. Observe agora que o tempo da consulta foi mais rápido, mas não se engane. Isso ocorre em função de que quando a consulta é executada pela segunda vez, a mesma deixa de ser uma consulta AD-HOC e fica armazenada em cache.
Agora você já pode parar o trace. Para isto, acesse o menu File à Stop Trace. Como o trace já foi realizado salvando as informações em arquivo, basta fechar a janela do Profiler.
Apesar de extenso, o conteúdo apresentado sobre o Profiler foi superficial e deve ser estudado de forma mais detalhada. Para isso, recomendamos a leitura do artigo sobre o Profiler da SQL Magazine, Edição 55.
Quando estamos buscando por um determinado assunto em um livro, a maneira mais rápida e fácil é pesquisar o índice do livro para assim acharmos a página que contém tal assunto. Assim é o uso do índex dentro do banco de dados. Quando estamos trabalhando com queries e estas apresentam falta de desempenho, o primeiro recurso que utilizamos, e, que quase sempre resolve o nosso problema, é o uso de índex nas tabelas.
Antes de programar os indexes já vimos que conhecer o cenário e utilizar ferramentas de análise e monitoramento é importante para termos noção exata do que estamos fazendo. Portanto quando estamos no ponto de empregar os índex nas tabelas, passamos a ter outras preocupações, pois ao implementar um índex, operações como INSERT, UPDATE e DELETE perderão desempenho. Então temos mais este ponto de atenção e de confirmação de que implementar queries de forma a ganhar desempenho na base de dados é um exercício bem complicado e deve ser feito de forma inteligente.
Índices são estruturas que possuem algoritmos otimizados para acessar dados. No SQL Server o índex trabalha com o algoritmo B-Tree. Este algoritmo é construído de maneira a armazenar informações da tabela de forma inteligente quando precisa ser consultado. Podemos dizer que um índex é uma cópia da tabela original, mas armazenada de forma inteligente.
O SQL Server atualiza o índice com dados da tabela origem cada vez que a tabela recebe novos dados ou quando seus dados são atualizados. Quando isto ocorre, o resultado das consultas DML (INSERT, UPDATE e DELETE, por exemplo) perdem desempenho. Observe na Figura 5 que quando uma consulta T-SQL é acionada para buscar um determinado valor dentro de uma tabela, o acesso a este valor é feito através do índice escrito para essa tabela e deste ponto o SQL Server monta o result set de resposta. Diferente das consultas que não manipulam dados; as DMLs fazem com que a B-TREE seja reestruturada realocando valores nos níveis (levels) root, intermediate ou leaf de acordo com os dados que estão sendo inseridos, modificados ou retirados.
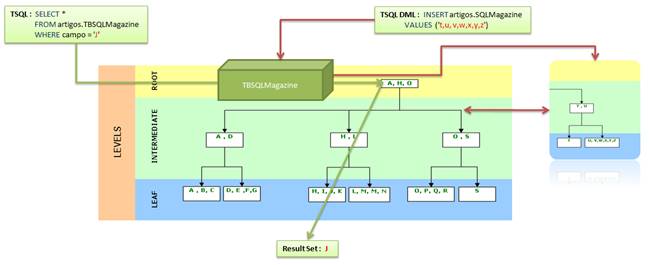
Figura 5. T-SQL consultando um valor pelo índex e uma consulta DML incrementando o índex.
Os tipos existentes de índex são: Clusterizado e Não-Clusterizado. Tanto o índex clusterizado como o não-clusterizado acessam o algoritmo B-Tree, então, qual a diferença? A resposta é que o índex clusterizado quando acessa o level folha (leaf level) o ponteiro já aponta diretamente para os dados que estão sendo pesquisados, e o não-clusterizado, em vez de apontar diretamente para os dados, primeiro encontra um valor referência que daí aponta para os dados.Uma consideração importante ao implementar um índex clusterizado é que o SQL Server só permite um índex por tabela, e como boas práticas, este deve ser criado em uma coluna de chave primária. Ao utilizar o não-clusterizado, você pode implementar até 249 índex, e como boas práticas, é aconselhável que tenhamos no máximo 5 índex para cada tabela. É comum que encontrarmos mais de 5 índices em tabelas, mas como citado, faz parte das boas práticas aconselhadas pela Microsoft termos poucos índices.
Para criar um índex utilize a seguinte sintaxe:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON <OBJECT> ( column [ ASC | DESC] [ ,…n ] )
[ INCLUDE ( column_name [ ,…n ] ) ]
[ WITH ( <relational_index_option> [ ,…n ] ) ]
[ ON { partition_scheme_name ( column_name )
| filegroup_name
| default
}
] [ ; ]
Caso seja necessário desabilitar o índex utilize o comando:
ALTER INDEX { index_name | ALL }
ON <object>
DISABLE [ ; ]
Quando um índex é desabilitado, você deve recriá-lo toda vez que quiser tê-lo em sua tabela novamente, pois quando você o recria, o SQL Server faz a população do mesmo com os dados atuais da tabela. Para reconstruir um índex, utilize o seguinte código:
ALTER INDEX { índex_name | ALL }
ON <object>
REBUILD [ ; ]
Para mais informações sobre o assunto acesse ‘Books Online’, procurando por: “Covering Index” e “Reational Index”.
O DTA ou Data Base Engine Tuning Advisor é uma ferramenta que através da análise sobre as queries de entrada no analisador (workload), comparando o custo de cada uma para a base de dados, indica qual a melhor estrutura para suas tabelas, particionamentos ou views indexadas para resolução de problemas de desempenho. Como já vimos no tópico sobre o Profiler, é interessante que você realize as análises utilizando um arquivo trace gerado pelo Profiler. Dessa forma, você poderá filtrar as análises do DTA estreitando-as a analisar somente queries que quiser; desta maneira você não criará índex nem de menos nem demais e não terá o trabalho de analisar todas as consultas da base de dados a próprio punho. Para utilizar o DTA, vamos rever alguns pontos de observação:
- O DTA veio no
lugar do Index Tuning Wizard (ITW) utilizado nas versões anteriores ao SQL
Server 2005;
- Você pode utilizar um arquivo criado pelo Profiler e analisá-lo no DTA;
- Você pode exportar os relatórios de melhoria do DTA em arquivos XML para utilizá-los em analisadores de outros SGBDs;
- Você pode utilizá-lo para analisar uma única query selecionando-a e escolhendo a tool do DTA no menu tools.;
- É importante limitar o tempo de análise do DTA quando estiver com muitas consultas complexas para serem analisadas, senão o DTA passará horas ou até dias, dependendo da quantidade de consultas para dar o retorno;
- É importante especificar para o DTA em qual base de dados e tabelas ele rodará as analises;
- As análises são baseadas no custo de cada consulta que o query optimizer envia ao DTA mediante pesquisas na base de produção. O DTA simula várias combinações de indexação até não existirem maneiras de otimizar a consulta (Figura 6), para somente então, gerar o relatório final;
- Realize as análises do DTA utilizando um backup da sua base de produção em outro servidor para não perder desempenho, pois as análises do DTA são realizadas na base de produção;
- O resultado do DTA sempre consiste em criar uma nova estrutura e nunca realizar um delete em alguma existente. Por este motivo, sempre verifique se é necessário manter estruturas de índices na qual você já utilizou em algum momento.
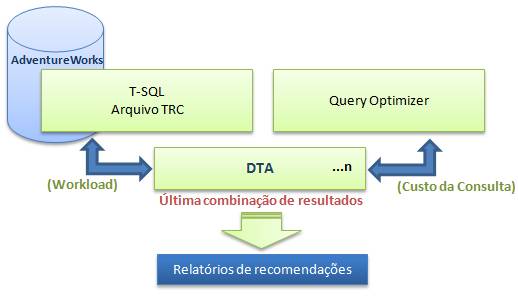
Figura 6. Representação do DTA realizando uma otimização de uma TSQL.
O DTA é uma ferramenta fácil de utilizar e lhe oferece várias horas de tranqüilidade, pois realiza todas as análises de forma automática e facilita a vida dos nossos clientes.
Você pode utilizar o DTA para realizar o tuning de um servidor de produção sem realizar backups. Portanto, para agilizar e automatizar a análise, o aconselhável a fazer é utilizar Jobs que iniciem um trace com o Profiler e de tempo em tempo este trace é parado e importado para dentro das análises do DTA. Escolha a opção para criação de índex online para não bloquear nenhuma transação que possa estar em concorrência com as análises (veja as limitações de uso desta opção para as edições do SQL Server 2005 no books online).
Para configurar o DTA, acesse-o, como indica a Figura 7. Selecione em Workload um arquivo TRC (trace do profiler), de acordo com a Figura 8, e especifique as opções de tuning na guia “Tuning Options”, apresentado na Figura 9.

Figura 7. Abrindo o DTA (O DTA também pode ser aberto através do SSMS).
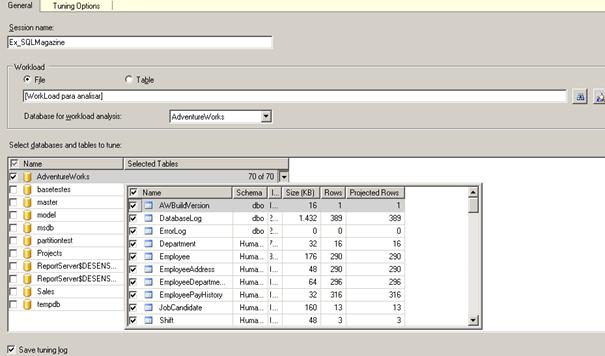
Figura 8. Configurando a tela “General” do DTA.
No campo “Session name“ (Figura 8) indique um nome de preferência ou deixe o padrão. Após fazer isso, indique o “Workload” (File ou Table). Neste caso, utilize o trace que fizemos na sessão do Profiler. Depois é só indicar a base de dados e tabelas (podendo ser selecionadas na lista dropdown ao lado direito do nome da base de dados) para análise.
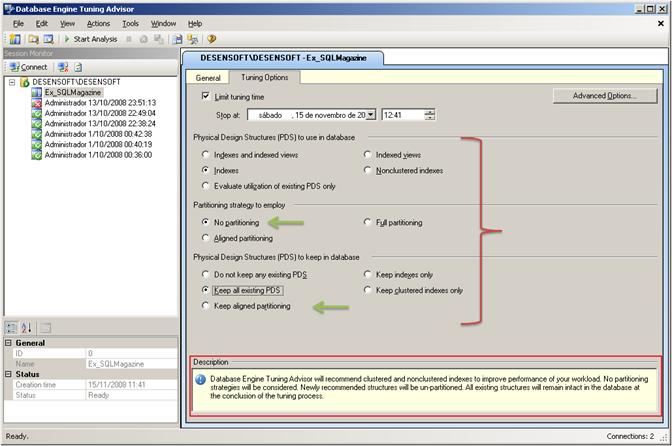
Figura 9. Configurando as opções do tuning.
Na guia “Tuning Options” você indica como as análises devem se comportar e quais tipos de análises serão realizados. Como a tela é bem didática, vamos fazer somente algumas considerações; veja que na parte inferior da tela existe o campo “Description”, este campo dá dicas do comportamento da análise a cada escolha que você realiza nesta tela. Para efeito de teste, selecione as duas opções marcadas na Figura 9, e observe que a descrição apontará um erro. A falha está em optar para que o DTA não trabalhe com estratégias de particionamento e ao mesmo tempo pedir para manter os particionamentos alinhados. Como já foi dito, mesmo não existindo um tempo limite é importante limitar este tempo de analise quando estiver trabalhando em uma base de dados de produção. Por este motivo, mantenha o campo “Limit Tuning Time” marcado. Após todas as configurações, clique em “Start Analysis” para permitir o início das analises.
Quando o DTA inicializa as análises ou termina de realizá-las, a tela principal do DTA é configurada com mais três guias, são elas: Progress, que indica o progresso da análise; Recommendations, que são as recomendações feitas para ganho de performance; e por último a Reports, que faz um resumo da análise. Para utilizar as recomendações feitas pelo DTA, basta selecionar na guia Recommendations a coluna Definitions e clicar no link para que o SQL exiba o script de criação de uma nova estrutura para melhorar a performance das queries contidas no arquivo trace (observe a Figura 10).
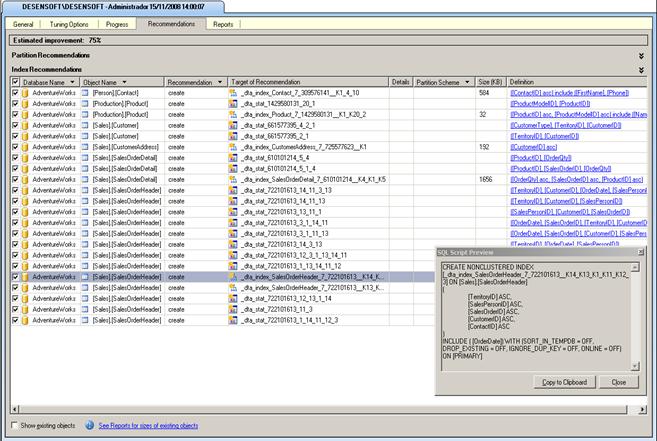
Figura 10. Utilizando os scripts para melhoria de desempenho das queries.
Para criar as indexes, Estatísticas e/ou Particionamentos, basta clicar no botão “Copy to Clipboard” da janela popup, e utilizar o script dentro do SSMS.
De acordo com o DTA, se programarmos todas as recomendações que ele propôs para o trace que fizemos (uma única T-SQL), o desempenho da consulta pode melhorar em até 75%. Então, siga as recomendações e após implementar todas elas, teste a consulta da Listagem 1 novamente. Perceba que o DTA não pode melhorar a consulta, pois todas as estruturas necessárias para aumentar o desempenho desta T-SQL já foram então, implementadas anteriormente por você.
Caso não queira utilizar as recomendações do DTA no mesmo momento, você pode salvá-las para utilizar futuramente. Pode também re-analisar na guia reports, vários relatórios gerados para cada item analisado.
Uma maneira de conhecer tudo o que as ferramentas do SQL Server 2005 pode lhe trazer é fazer da utilização do Books Online um hábito, pois nele você encontra especificações extremamente ricas para cada mínima coisa que você está pesquisando. Este conselho fica para estudar ainda mais o DTA.
Conclusão
Com um cenário tão complexo no qual estamos, precisamos apreender a trabalhar com o que temos em mãos e buscar aprimorar nosso conhecimento cada vez mais. A atualidade obriga empresas terem lucros altos, mas investindo pouco. Portanto, é importante que cada DBA faça sua parte nessa estratégia. Conhecer não só as ferramentas que nos cercam, mas também o cenário como um todo é muito importante, pois a cada dia surgem novas tecnologias e devemos estar atualizados; Então o artigo foca a importância da visão sistêmica no dia-a-dia e também o que temos de ferramentas para trabalhar dando desempenho total para as nossas queries.
De que se trata o artigo?
Este artigo utiliza o Database Engine Tuning Advisor abordando boas práticas de sua utilização e os cuidados quanto a implementação de índices
Para que serve?
A tecnologia apresentada nos permite analisar de forma minuciosa tudo que pode ser melhorado em uma querie e em outras estruturas como uma view indexada, também nos oferece agilidade e praticidade para tal análise e implementação.
Em que situação é útil?
Útil para ganho de desempenho das queries que possam estar com certa lentidão ao serem utilizadas e também para encontrarmos possíveis erros lógicos e falhas de disco, já que temos como melhor prática, o uso do Profiler, e ele nos mostra tudo isso.
.
Referências
SQL Server Bible - Paul Nielson, Wiley
A Questão da Informação - Publicação da revista São Paulo, n 4, 1994.
Training Kit – Publicado por Solid Quality Learning, 2007.
Inside Microsoft SQL Server 2005: T-SQL Programming – Itzik Ben-Gan, Dejan Sarka e Roger Wolter.

- Diferenças entre SEQUENCES x IDENTITY no Microsoft SQL Server 2012SQL
- Utilizando FILETABLE no SQL Server 2012SQL Server
- Utilizando SEQUENCES no Microsoft SQL Server 2012SQL
- Exportação de dados do SQL Server para o Oracle com assistente de importação do SQL ServerSQL
- Dica Importante SQL Server 2008 Management StudioSQL
