
Desenvolvimento - SQL
Inovações na linguagem TSQL do SQL Server 2005
Nesse artigo irei tratar de algumas das modificações na linguagem Transact SQL, linguagem de consulta utilizada pelo SQL Server desde a sua primeira versão, compatível com o SQL Ansi Padrão, mas que contém algumas características que visão facilitar a vida dos desenvolvedores da plataforma Microsoft.
por Gilberto NetoNesse artigo irei tratar de algumas das modificações na linguagem Transact SQL, linguagem de consulta utilizada pelo SQL Server desde a sua primeira versão, compatível com o SQL Ansi Padrão, mas que contém algumas características que visão facilitar a vida dos desenvolvedores da plataforma Microsoft.
Nesse artigo irei falar sobre as novas funcionalidades seguintes:
1. Row_Number()
2. Rank()
3. Pivot
4. UnPivot
5. Criptografia
6. Tratamento de erros
7. Novos tipos de gatilhos (triggers)
8. .Net no SQL Server 2005
Então vamos nessa!
1. Row_Number()
Começaremos falando da nova função ROW_NUMBER() que serve para numerar os registros do resultado de uma consulta. Na versão anterior, era necessário criar uma tabela temporária (as famosas # e ##) ou então uma variável do tipo Table (inovação introduzida na versão 2000 do SQL Server), com um campo do tipo Identity (campo seqüencial gerado automaticamente a cada inserção) e depois realizar uma consulta nessa tabela ordenando por essa coluna, abaixo temos o código TSQL para isso:
DECLARE @TESTE TABLE(NOME VARCHAR(50), ROWNUM INTEGER IDENTITY(1,1)) INSERT INTO @TESTE SELECT NAME FROM SYSOBJECTS SELECT * FROM @TESTE ORDER BY ROWNUM
Podemos observar que não é sempre que é possível utilizar essa construção principalmente se não estiver encapsulada dentro de uma Stored Procedure, entretanto na nova versão temos uma função que já encapsula essa funcionalidade, a ROW_NUMBER(), com ela podemos colocar em qualquer consulta que já retornará o número do registro e ainda temos a facilidade de definir sobre qual campo e qual ordenação você deseja que seja feita a numeração, segue o mesmo exemplo (resultado na figura 1):
SELECT ROW_NUMBER() OVER (ORDER BY NAME) AS ROWNUM, * FROM SYSOBJECTS
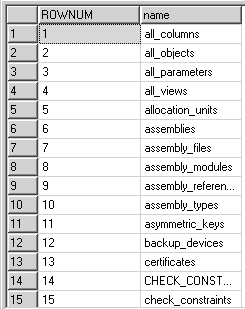
Figura 1. Resultado da consulta com ROW_NUMBER()
No exemplo estamos numerando a partir da ordenação da coluna NAME crescentemente.
Note que a ordenação pode ser crescentemente ou decrescentemente, bastando colocar ORDER BY NAME ou ORDER BY NAME DESC, no exemplo citado.
2. Rank()
Função utilizada para fazer o ranking do resultado de uma consulta. Ainda é possível agrupar dados pra fazer o ranking de acordo com esse agrupamento (através do PARTITION BY). Nas versões anteriores, esse tipo de consulta era possível mas sua performance e complexidade chegavam a ser desmotivante.
Exemplo (resultado na figura 2):
USE AdventureWorks GO SELECT i.ProductID, p.Name, i.LocationID, i.Quantity, RANK() OVER (PARTITION BY LocationID order by i.Quantity) as RANK FROM Production.ProductInventory i JOIN Production.Product p ON i.ProductID = p.ProductID ORDER BY Name
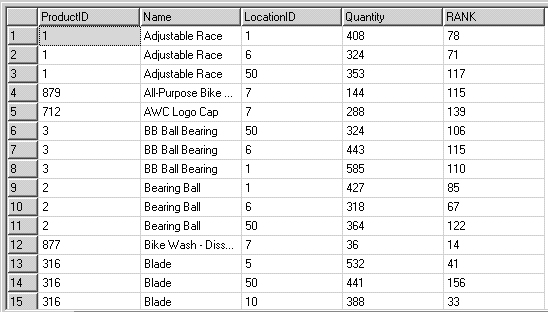
Figura 2. Resultado da consulta usando o RANK()
3. Pivot
Uma das funcionalidades mais deficientes era a dificuldade de se criar uma tabela conhecida como PIVOT (Trocar linhas por colunas, sintetizar alguns registros transformando-os em colunas). Antigamente para tal efeito somente utilizando cursores ou loops, pois era necessário percorrer todo o conjunto de registros e ir sintetizando e criando as colunas dinamicamente. Caso fosse um pivot simples e estático ainda tínhamos a possibilidade de utilizar o CASE, mas geralmente não era o caso. Para minimizar esse processamento agora temos o operador relacional conhecido como PIVOT que é utilizado para esse fim. Exemplo (veja o resultado na figura 3):
USE AdventureWorks GO SELECT VendorID, [164] AS Emp1, [198] AS Emp2, [223] AS Emp3, [231] AS Emp4, [233] AS Emp5 FROM (SELECT PurchaseOrderID, EmployeeID, VendorID FROM Purchasing.PurchaseOrderHeader) p PIVOT ( COUNT (PurchaseOrderID) FOR EmployeeID IN ( [164], [198], [223], [231], [233] ) ) AS pvt ORDER BY VendorID
Podemos notar que utilizamos um select em outro select com o operador relacional PIVOT pra sintetizar os valores das quantidades de vendas (PurchaseOrderId) de cada empregado incluído no conjunto definido na cláusula IN.
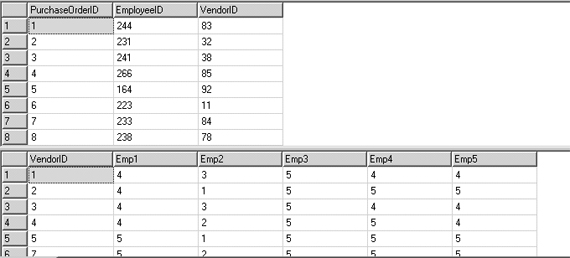
Figura 3. Resultado sem o operador relacional PIVOT - registros gravados no banco - e o resultado utilizando o operador, sintetizando as informações
4. UnPivot
Esse operador reverte as colunas sintetizadas em registros, ou seja, reverte uma tabela gerada pelo operador pivot de volta para os registros originais.
5. Criptografia
Não tínhamos funções para criptografar e descriptografar dados, no máximo podíamos utilizar as funções PWDENCRYPT E PWDCOMPARE para criptografar e comparar senhas criptografadas, ou seja, uma vez criptografada não tínhamos como recuperar essa informação apenas comparar essa informação criptografada com um dado qualquer. Na versão 2005, existem algumas formas de criptografar, irei explanar sobre as funções ENCRYPTBYPASSPHRASE e DECRYPTBYPASSPHRASE que respectivamente criptografam e descriptografam qualquer informação baseada em uma chave, que dessa forma contendo essa chave podemos ter a informação no seu estado normal novamente. Exemplo (ver figura 4):
DECLARE @FRASE NVARCHAR(4000) SET @FRASE = "CRIPTOGRAFIA" DECLARE @SENHA NVARCHAR(4000) SET @SENHA = "FENIX" DECLARE @CRIPTOGRAFADO VARBINARY(4000) SET @CRIPTOGRAFADO = ENCRYPTBYPASSPHRASE(@FRASE, @SENHA) DECLARE @DESCRIPTOGRAFADO NVARCHAR(4000) SET @DESCRIPTOGRAFADO = DECRYPTBYPASSPHRASE(@FRASE, @CRIPTOGRAFADO) PRINT @FRASE PRINT @SENHA PRINT @CRIPTOGRAFADO
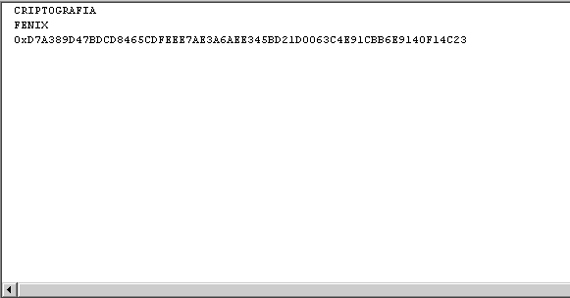
Figura 4. Resultado das variáveis mostrando a frase, senha e a senha criptografada
Note que as funções são simples, possuindo apenas dois parâmetros cada, a ENCRYPTBYPASSPHRASE tem como parâmetros a senha a criptografar e a chave de criptografia, assim como a DECRYPTBYPASSPHRASE que tem como parâmetros o dado criptografado e a chave de criptografia, que deve ser a mesma com a qual o dado foi criptografado.
6. Tratamento de erros
Tratávamos os erros verificando o valor da variável global @@ERROR que guardava o código de erro da última instrução TSQL executada, quando fosse igual a 0, então não tinha ocorrido erro algum nessa instrução. Na nova versão, temos um bloco de tratamento de erros que consiste na seguinte sintaxe:
BEGIN TRY ... END TRY BEGIN CATCH ... END CATCH
EXEMPLO (ver figura 5):
USE AdventureWorks;
GO
BEGIN TRANSACTION;
GO
BEGIN TRY
-- Generate a constraint violation error.
DELETE FROM Production.Product
WHERE ProductID = 980;
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() as ErrorState,
ERROR_MESSAGE() as ErrorMessage;
END CATCH
GO

Figura 5. Visualizando o erro gerado
7. Novos tipos de gatilhos (triggers)
Até a versão 2000 do SQL Server tínhamos triggers (gatilhos) que respondiam a eventos como INSERT, UPDATE, DELETE, com a nova versão foram incluídas as triggers que respondem a eventos DDL (Data Definition Language) como CREATE, ALTER E DROP.
Como exemplo, vamos criar uma trigger de segurança para que não seja possível excluir (DROP) e dessa forma alterar o SCHEMA do banco de dados, ou seja, nenhuma tabela poderá ser excluída:
USE MASTER CREATE TRIGGER SEGURANCA ON DATABASE FOR DROP_TABLE AS PRINT "PARA APAGAR TABELAS DESABILITE A TRIGGER SEGURANCA" ROLLBACK GO
8. .Net no SQL Server 2005
O SQL Server 2005 tem grande integração com a tecnologia .Net, através da integração com a CLR (Common Language Runtime) é possível criar Stored Procedures e Triggers ou User-Defined Functions utilizando código gerenciado em diversas linguagens como C#, VB.Net, e tantas outras linguagens da plataforma .Net. Tanto os códigos criados usando TSQL quanto código gerenciado do .net framework rodarão no servidor aumentando a eficiência e diminuindo o tráfego de informações na rede. Devido ao paralelismo e aos planos de execução do processador de consultas do SQL Server, as funções que utilizem código gerenciado terão uma grande performance, tornando-se uma ótima opção para o desenvolvedor.
Essas foram algumas das inovações, ainda outras existem fazendo com que o SQL Server 2005 seja uma poderosa ferramenta e um grande SGBD para suas aplicações com um custo/benefício muito interessante.
Aguarde em outros artigos algumas outras novidades para implementadores e também as novidades que vão ajudar a facilitar a vida de muitos DBAs poupando trabalho e proporcionando uma maior segurança.

- Diferenças entre SEQUENCES x IDENTITY no Microsoft SQL Server 2012SQL
- Utilizando FILETABLE no SQL Server 2012SQL Server
- Utilizando SEQUENCES no Microsoft SQL Server 2012SQL
- Exportação de dados do SQL Server para o Oracle com assistente de importação do SQL ServerSQL
- Tunning Index com o DTASQL
