
Desenvolvimento - SQL
Simplifique as SQL_Variants
Aprenda qual o sentido das variantes no SQL Server 2000 e como usá-las corretamente.
por Josef FinselDurante anos, as pessoas têm discutido sobre se deveriam usar Variantes no Visual Basic, porque embora elas sejam flexíveis, usá-las incorretamente pode causar erros. Agora que o SQL Server 2000 suporta o tipo de dados Variant, esta mesma flexibilidade está disponível dentro do SQL. Você pode usar as Variantes em dois lugares no SQL Server 2000: como uma coluna de dados dentro de uma tabela, e como uma variável dentro de uma instrução Transact-SQL (T-SQL) ou stored procedure.
Considere estes dois números de telefone: 8008485523 e (800) 848-5523. Eles representam a mesma informação ao observador comum, mas são itens completamente diferentes para o computador. Tente essa pequena experiência para ver como é diferente: no Enterprise Manager, abra o banco de dados Pubs, vá para a seção Tables e clique com o botão direito para criar uma tabela nova. Dentro da tabela, crie uma única coluna chamada VariantPhoneNumber e defina-a como SQL_Variant (veja Figura 1). Observe que você não tem nenhum controle sobre o comprimento de suas colunas. Salve a tabela nomeando-a VariantTest.
A flexibilidade do tipo de dado SQL_Variant permite armazenar múltiplos tipos de dados. Infelizmente, essa flexibilidade tem um preço – estes tipos de dados múltiplos podem levar a erros. Aqui o SQL Server mistura dados numéricos e caracteres na mesma coluna de uma tabela.
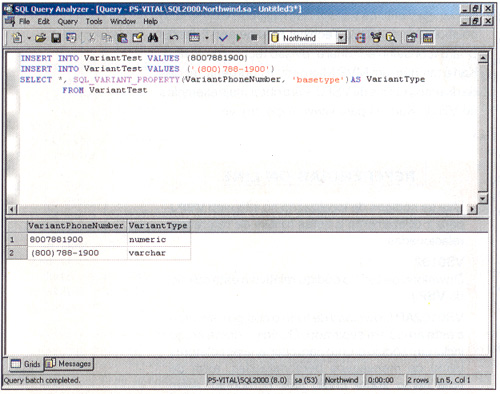
Figura 1: A Flexibilidade SQL_Variant tem um preço
A tabela VariantTest aparece em sua lista de tabelas; clique com o botão direito na tabela e selecione Open | Return para todas as linhas. Uma tabela em branco se abre. Se você estiver familiarizado com o uso do Enterprise Manager, sabe que as linhas podem ser adicionadas digitando os dados da coluna diretamente numa linha em branco, na grade, para executar aquela instrução. Tente digitar o primeiro número de telefone no parágrafo anterior. Você recebe uma mensagem de erro, dizendo: “Esta célula não pode ser editada”. O Enterprise Manager precisa ter uma vaga idéia do tipo de dados que você está entrando; se ele não associar uma diferença, padroniza a coluna como binária e você não consegue editá-la.
Os dados não podem ser digitados diretamente na tabela, mas através da maneira antiga. Inicie o SQL Query Analyzer e emita estes três comandos:
Listagem 1: Inserindo e recuperando dados da tabela VariantTest
INSERT INTO VariantTest VALUES (8007881900)
INSERT INTO VariantTest VALUES ("(800)788-1900")
SELECT *, SQL_VARIANT_PROPERTY (variantphonenumber, "basetype") FROM VariantTest
Esses comandos T-SQL inserem dois registros numa VariantTest, exibindo os dados inseridos, e o tipo de dados interpretado pelo SQL. Não há nenhum problema em ver os dados, porque o Query Analyzer converte todos os dados numa string em vez de binário. A desvantagem é que você não pode editar os dados no Query Analyzer. Você vê os registros voltarem, um como um tipo de dados numeric e o outro como um tipo de dados varchar.
Entretanto, ao abrir a tabela no Enterprise Manager, você vê os dois registros com ambos os campos exibindo como . Ao criar as colunas como Variants dentro de uma tabela SQL, lembre-se que você não pode editá-las nem exibi-las dentro do Enterprise Manager, porque ele as interpreta como campos binários.
Domine o Perverse Type Casting
Outro problema encontrado ao usar Variants para um tipo de coluna é algo coloquialmente denominado "perverse type casting". Para efetuar inserções, crie uma stored procedure usando a tabela VariantTest. Você precisa construir uma stored procedure, porque não há outra maneira de entrar com dados Variants diretamente numa instrução SQL. O T-SQL lhe exige a definição dos dados primeiro – da mesma maneira como você fez nos comandos INSERT – colocando aspas simples ao redor dos valores. Para demonstrar o perverse type casting, crie uma procedure que leve uma Variant para o parâmetro e depois insira o parâmetro sem qualquer conversão. Isso força o SQL Server a fazer a conversão, na melhor das hipóteses:
Listagem 2: Criando procedure para inserir valores na tabela VariantTest
CREATE PROCEDURE TestVariant @Var sql_variant AS INSERT INTO Varianttest VALUES(@Var)
Agora você precisa esvaziar a tabela. Então, execute o procedimento armazenado com valores diferentes:
Listagem 3: Executando o procedures TestVariant
TRUNCATE TABLE VariantTest EXEC TestVariant 12345 EXEC TestVariant "12345" EXEC TestVariant 12345.0 EXEC TestVariant a
Surpreendentemente, o SQL Server lança cada um destes valores como varchar, nvarchar, numeric e int (consulte a ordem de classificação na Tabela 1).
Tabela 1: O SQL Server Classifica os Valores da SQL_Variant. Ao classificar SQL_Variants por valor, o SQL Server classifica-os automaticamente por tipo de dados e depois por valor. Neste caso, o valor "a" classifica a seqüência esperada, porque o tipo de dado nvarchar classifica mais alto que varchar e mais baixo que numeric.
| Valor | Tipo |
| 12345 | varchar |
| a | nvarchar |
| 12345.0 | numeric |
| 12345 | int |
Eu não estava esperando este resultado, que ocorre porque o SQL determina a ordem de classificação por tipo de dados primeiro e depois pelo valor. A ordem exata é primeiro os dados de caractere; segundo, os dados numéricos exatos (int, numeric, e assim por diante); terceiro, os dados numéricos aproximados (ponto flutuante e real) e por último datetime (data e hora). Esta é uma das razões pela qual você não pode incluir uma Variant como parte da chave primária. As chaves primárias devem ser únicas e, embora você tenha inserido quatro valores distintos, três deles parecem ser iguais (12345) mesmo que o SQL Server os interprete como valores diferentes.
A segunda razão é que você não pode usar uma Variant como chave primária, porque a chave primária numa tabela é um índice. O SQL Server não lhe permite definir o tamanho máximo da coluna que você cria dentro de uma coluna SQL_Variant. Esta restrição traz alguns casos interessantes ao indexar uma coluna SQL_Variant. O tamanho do comprimento total da chave de um índice é limitado a 900 bytes e o SQL Server não criará o índice se qualquer linha possuir dados que fazem a chave de índice ir acima de 900 bytes. Você pode acrescentar uma coluna SQL_Variant ao índice, mas você recebe um aviso de que o índice não será criado.
Acrescentar uma linha numa tabela indexada que faz com que o índice seja maior que 900 bytes, não é o bastante. Primeiro, crie um índice. Depois, tente inserir uma string grande:
Listagem 4: Criando índice na tabela VariantTest
CREATE INDEX IX_VariantTest ON
VariantTest(VariantPhoneNumber)
ON [PRIMARY]
GO
INSERT INTO VariantTest
values(replicate("A",1000))
Insert a 1000 char string
A atualização falha com uma mensagem de erro dizendo que o índice é muito grande. Para que você possa usar a SQL_Variant como um índice em sua tabela, você precisa acrescentar o código ao seu tratador de erro para processá-lo. Se não for o bastante, toda a documentação lhe diz para converter os dados a um tipo de dados non-Variant, antes de armazená-lo em uma coluna SQL_Variant.
Controle as SQL_Variants
s As SQL_Variants oferecem uma nova flexibilidade em stored procedures, especificamente nas funções definidas pelo usuário (User-Defined - UDFs). As mesmas propriedades que tornam as Variants responsáveis pelos tipos de coluna podem ser um recurso em criar UDFs mais flexíveis. Uma stored procedure nada mais é que um grupo de instruções T-SQL que você armazena no servidor e que funciona da mesma maneira que um VB Sub. Passe os parâmetros ByVal ou ByRef e retorne os dados. Como as UDFs são novas no SQL Server 2000, estas são as funções equivalentes no VB criadas para abrir o SQL Server, permitindo a reutilização do código. Você pode criar dois tipos principais de função no SQL Server 2000: as que retornam um valor simples e as que retornam um rowset (conjunto de linhas).Antes de aprender algumas das coisas caprichadas que você pode fazer numa função, primeiro você tem de entender as limitações das funções no SQL Server. O mais importante é que uma UDF não se permite ter qualquer efeito colateral; ou seja, não é permitido fazer qualquer mudança nos dados. O escopo de uma UDF é semelhante a uma função Private em VB que não pode mudar nada, exceto os dados passados por ela (embora possa consultar o banco de dados para obter outras informações).
Algo que sempre senti nas versões anteriores do SQL era a falta de uma função MAX. Você não pode pegar duas colunas de dados e retornar a maior das duas, porque MAX é uma palavra específica usada para selecionar o valor máximo de uma coluna de dados, de preferência entre dois valores. No SQL Sever 2000, você pode evitar esta limitação criando uma UDF. Certifique-se de não estar tentando comparar dois tipos de dados diferentes. Se você o fizer, então o SQL Server utiliza a família de tipos de dados para determinar o maior dos dois. Não levando isso em conta pode haver conseqüências não intencionais, como devolver 1 como o valor máximo ao comparar o numérico 1 e o caractere 4.
Você achará familiar a sintaxe para UDFs, embora haja algumas diferenças entre SQL e VB (veja Listagem 1). Primeiro, defina o nome da função - neste caso, MyMax. Depois, defina os parâmetros usados pela função. Para que esta função seja flexível, você precisa fixar os parâmetros como SQL_Variants. Defina também o tipo de dados do valor a retornar, novamente um SQL_Variant. Por enquanto, o código é a fórmula padrão Max, a única diferença é a criação de uma variável temporária para manter o valor de retorno, porque você pode definir somente um retorno na função. Embora a utilização das Variants ofereça flexibilidade para usar a mesma função com múltiplos tipos de dados, elas criam uma quantidade pequena de código extra (overhead). Você precisa distinguir a família do tipo de dados dos dois parâmetros, antes de avaliá-los, para determinar qual é o maior. Utilize o mesmo código para ambos os parâmetros, e então atribua uma UDF separada chamada VarDataFamily. Determine o tipo de dados básico com esta função e depois use a instrução CASE do T-SQL para nomear a família.
Este código T-SQL demonstra tanto a nova funcionalidade das UDFs como a utilidade dos tipos de dados SQL_Variant. Embora o tipo de dados SQL_Variant possa causar problemas se usado para definir uma coluna numa tabela, é extremamente útil para definir UDFs que você pode sobrecarregar. A mesma função pode tratar tipos de dados múltiplos.
Listagem 1: Função VarDataFamily
--Função VarDataFamily
--Determina a família de dados atrás de uma
--SQL Variant e retorna aquela família como uma string
CREATE FUNCTION VarDataFamily(@VarPrm SQL_Variant)
RETURNS varchar(20)
AS
BEGIN
DECLARE @DataType varchar(20)
DECLARE @RetVal varchar(20)
SET @DataType = convert(varchar(20),
SQL_VARIANT_PROPERTY(@VarPrm, "basetype"))
SELECT @RetVal =
CASE
WHEN @DataType IN
("char", "varchar", "nchar",
"nvarchar") THEN "unicode"
WHEN @DataType IN
("bit", "tinyint", "smallint",
"int", "bigint", "smallmoney",
"money", "decimal")
THEN "exact number"
WHEN @DataType IN ("smalldatetime","datetime")
THEN "datetime"
WHEN @DataType IN ("float","real")
THEN "approximate number"
ELSE "ERROR"
END
RETURN @RetVal
END
GO
--MyMax
--Procedimento armazenado para retornar o Max
CREATE FUNCTION MyMax
(@Prm1 SQL_Variant,
@Prm2 SQL_Variant)
RETURNS SQL_Variant
AS
BEGIN
DECLARE @RetVal SQL_Variant
DECLARE @Cvt1 SQL_Variant
DECLARE @Cvt2 SQL_Variant
DECLARE @Base1 SQL_Variant
DECLARE @Base2 SQL_Variant
SET @Base1 = dbo.VarDataFamily(@Prm1)
SET @Base2 = dbo.VarDataFamily(@Prm2)
--Se as bases combinam, permita o SQL
--tratar a conversão
IF @Base1 = @Base2
SELECT @Cvt1 = @Prm1, @Cvt2 = @Prm2
ELSE
SELECT @Cvt1 =
cast(@Prm1 as varchar(2048)),
@Cvt2 = cast(@Prm2 as varchar(2048))
--Retorne o Max
IF @Cvt1> @Cvt2
SET @RetVal = @Prm1
ELSE
SET @RetVal = @Prm2
RETURN @RetVal
END
Felizmente, O SQL Server agrupa e converte tipos de dados em famílias de tipos de dados. Se um parâmetro é um int e o outro um decimal, o SQL pega o int, converte-o implicitamente em um decimal para avaliar os dois. Agora que você sabe a qual família pertence ambos os parâmetros, pode dar o próximo passo. Deixe o SQL manipular a conversão implicitamente, se ambos os parâmetros pertencem à mesma família de tipo de dados. Converta-os em strings e os compare, se eles não pertencerem à mesma família. Em qualquer caso, você deve ter cuidado para retornar os parâmetros originais, não as variáveis convertidas.
Agora MyMax (‘4’, 1) retorna corretamente o caractere de tipo de dados “4”, em vez do tipo de dados numérico 1 que teria retornado se você não tivesse convertido as SQL_Variants antes de avaliá-las.
Você pode usar a sua função MyMax no banco de dados Pub, por exemplo, e também em outros bancos de dados. Existem duas opções para implementar o código em programas novos ao escrever uma função nova em VB. Uma opção é cortar e colar a função em todo o programa; a outra é colocar a função numa biblioteca onde seus programas podem consultar. Criar uma função em cada banco de dados é comparável a cortar e colar a função em todo o programa. As notícias boas são que você pode criar facilmente uma função para todos os seus futuros bancos de dados, criando-a no banco de dados SQL Server especial chamado Model. Da mesma maneira que você usa o projeto padrão como modelo para os projetos VB, você usa o banco de dados Model para criar um banco de dados novo. Ao criar as funções MyMax e VarDataFamily no banco de dados Model, você os tem em qualquer banco de dados que for criado.
Outra possibilidade é criar um banco de dados em seu servidor chamado Funções e armazenar todas as funções genéricas juntas. Não importa em qual banco de dados você esteja, uma função pode ser chamada usando o nome da função Funções. Esta é a maneira equivalente de se criar uma biblioteca de funções e inclusive o módulo no projeto.
Você irá ouvir falar mais sobre SQL_Variants. Como desenvolvedor, comece convertendo os seus aplicativos para utilizar o SQL Server 2000 e escrevendo novos aplicativos para aproveitar a nova funcionalidade oferecida. O melhor uso das Variants poderia estar em proporcionar as UDFs a flexibilidade de ter uma função que execute a mesma operação para tipos de dados diferentes, parecido com o sobrecarregamento orientado a objetos. Você encontrará maneiras singulares de utilizar as SQL_Variants, do mesmo modo que você tem o tipo de dados Variants no VB.
Sobre o autor
Josef Finsel é administrador de banco de dados sênior com PocketScript e está escrevendo um livro sobre administração de banco de dados para Apress.
Download do código referente a este artigo
Clique aqui para fazer o download.
- Diferenças entre SEQUENCES x IDENTITY no Microsoft SQL Server 2012SQL
- Utilizando FILETABLE no SQL Server 2012SQL Server
- Utilizando SEQUENCES no Microsoft SQL Server 2012SQL
- Exportação de dados do SQL Server para o Oracle com assistente de importação do SQL ServerSQL
- Tunning Index com o DTASQL
